Кластер Docker Swarm за 30 секунд
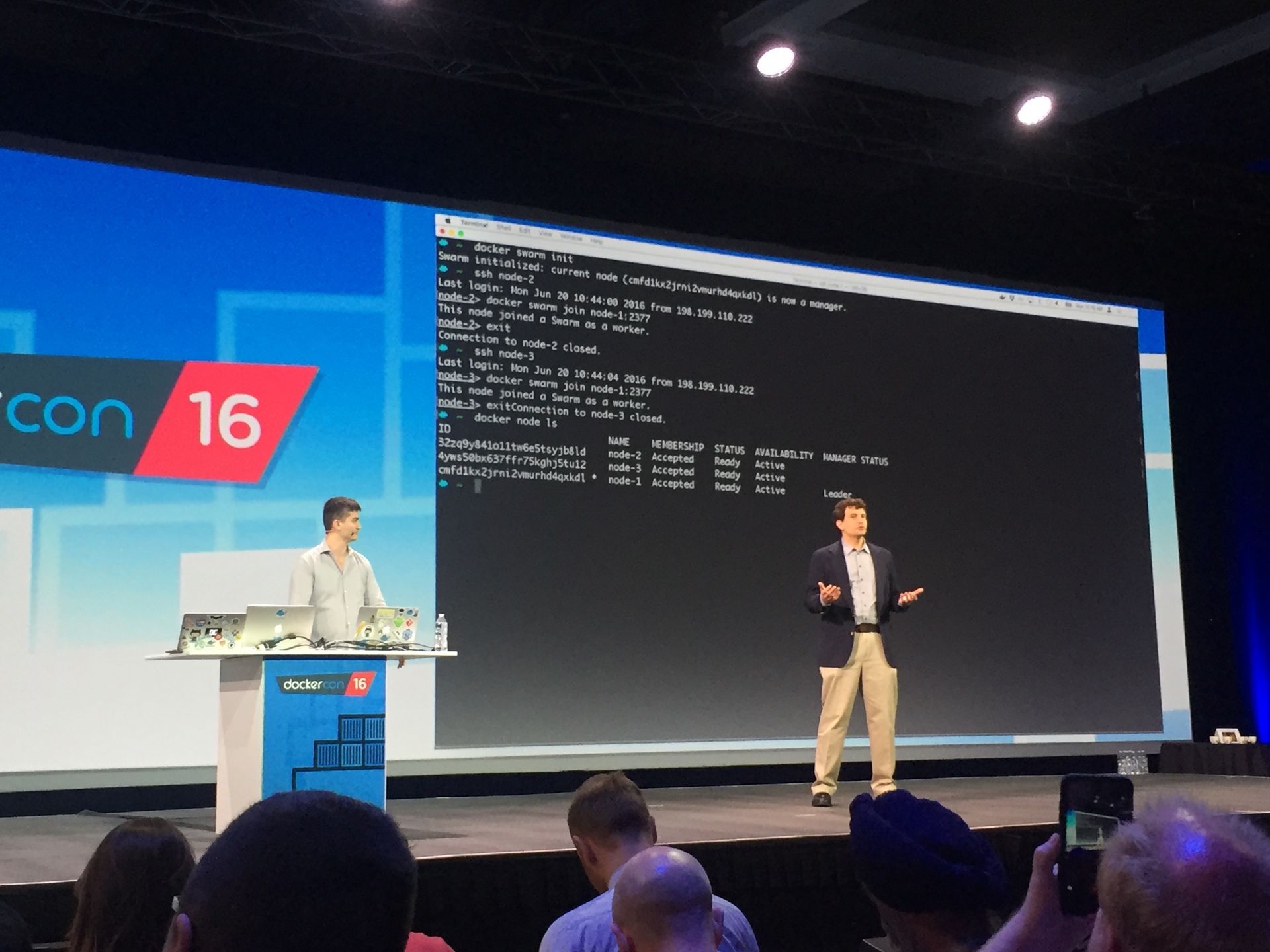
В этом июне, в качестве лейтмотива конференции DockerCon мы видели демо, в котором 3-узловой Swarm-кластер был создан за 30 секунд используя набор инструментов для кластеризации Swarm, интегрированную в Docker Engine 1.12.
Впечатляет, но естественно, мне нужно было попробовать сделать это самому, чтобы увидеть своими глазами.
Создание узлов в вашем Swarm
Я нашел самый простой путь. Для начала работы со Swarm (Роем) использовать docker-machine. Для создания хостов с установленным на них Docker Engine я использовал драйвер virtualbox’а, но вы можете использовать любой драйвер который вы хотите, например amazonec2.
Инициализация вашего менеджера

Присоединение воркеров (workers)
Скопируйте команду, отображенную ниже для первого узла из ваших воркеров, чтобы присоединить его к кластеру.
Теперь у вас есть Swarm-кластер!
Давайте что-нибудь развернем (deploy)
Первоначально мы хотим создать сеть верхнего уровня (оверлейную сеть), чтобы развернуть наше приложение.
До Docker Engine 1.12 оверлейные сети требовали внешнего хранилища ключ/значение, но с созданием распределенного хранилища в Docker 1.12 это больше не требуется.
Давайте развернем простое приложение Apache на публичном порту 5001. Я использую специальный образ Apache, найденный мной на DockerHub, который выводит ID контейнера, обслуживающего запрос. Позже это будет использовано для демонстрации балансировки нагрузки.
Вы можете использовать следующие команды, чтобы проверить ваш новый сервис:
Сетка маршрутизации
Добавления сетки маршрутизации и децентрализованной архитектуры в Docker 1.12 позволяет любым узлам-воркерам в кластере маршрутизировать (направлять) трафик к другим узлам.
В нашем веб-сервисе, (описанном выше) мы открыли кластерный (cluster-wide) порт 5001. Вы можете послать запрос на любой узел на порт 5001, и сеть маршрутизации направит запрос на тот узел, который запустил контейнер.
Балансирование нагрузки
Всегда когда создается новая служба, виртуальный IP создается вместе с этой службой. IPVS владеет (осуществляет) балансировкой нагрузки, высокопроизводительным уровнем 4 балансирования нагрузки, который встроен в ядро Linux.
Чтобы показать это, запустим curl несколько раз, для демонстрации изменение ID контейнера.
Балансировка нагрузки при помощи Docker 1.12 является контейнер-осведомленной (container-aware). Хост-осведомленная (host-aware) балансировочная система, такая как nginx или haproxy, удаляет или добавляет контейнеры требуемой конфигурации обновления балансирования нагрузки и перезапуска этих сервисов. Существует полезная библиотека, называемая Interlock, которая прослушивает Docker Events API и обновляет конфигурацию/осуществляет перезапуск сервиса “на лету”. Но этот инструмент больше требуется после нового добавления балансирования нагрузки в Docker 1.12.
Это не может быть так просто…
Эта картинка из Nigel Poulton очень хорошо обобщает различия между старым Swarm и новым Swarm.

Перевод картинки:
Старый путь (много шагов и команд не показано)
Новый путь
С Docker 1.12 вы также как и раньше можете инсталлировать внешние распределенные службы (consul, etcd, zookeeper), или отдельную службу планирования. Настройка TLS сквозная из коробки, нет “незащищенного режима”. У меня не существует никаких сомнений, что новый Docker Swarm является самым быстрым путем для получения запущенного и работающего docker-native кластера, готового быть развернутым в продакшн.
А что насчет большого масштабирования? Спасибо усилиям “капитана” Docker’a Chanwit Kaewkasi и DockerSwarm2000, они показали нам, что вы можете создать кластер из 2384 узлов и 96287 контейнеров.
Режим Swarm является самым оптимальным
Включать режим Swarm совершенно необязательно. Вы можете думать о режиме Swarm, как о наборе скрытых процедур, которые запускаются всего лишь командой
Swarm в Docker’е 1.12 также поддерживает согласования, плавающие обновления (rolling updates) образа, глобальные сервисы и сервисы по расписанию, базирующиеся на ограничениях.
Отказ узла в Docker Swarm
Также хочу затронуть тему отказа узлов в Docker Swarm. Команды, относящиеся к сервисам Docker Engine 1.12, являются декларативными. Например, если вы задаете команду «Я хочу 3 реплики данного сервиса», то кластер будет поддерживать это состояние.
В случае отказа узла контейнеры которого были задействованы, swarm обнаружит, что желаемое состояние не совпадает с действительным и автоматически исправит ситуацию путем перераспределения контейнеров на другие доступные узлы.
Чтобы это продемонстрировать, давайте зададим новый сервис с тремя репликами.
Запустите, чтобы проверить работу сервиса
Сейчас у нас есть по одному контейнеру на каждом из узлов. Давайте выведем из строя узел 3, чтобы посмотреть на регулирование swarm в действии.
Теперь желаемое состояние не совпадает с действительным. У нас есть только 2 действующих контейнера, тогда как мы обозначили 3 контейнера, когда запускали сервис.
Использование докер сервиса дает вам возможность увидеть, что количество реплик уменьшилось до двух, а затем снова вернулось к трем
docker service tasks web покажет вам новый контейнер, назначенный на другом узле вашего кластера.
Этот пример показывает только регулирование контейнеров на рабочих узлах. Совершенно другой процесс происходит, когда из строя выходит менеджер, особенно, если это лидер raft группы для решения задач консенсуса.
Глобальные сервисы
Глобальные сервисы полезны, когда вы хотите создать контейнер на каждом узле вашего кластера. Подумайте о ведении протокола или мониторинге.
Помните, я говорил, что сервисы являются декларативными? Когда вы добавляете новый узел к вашему кластеру, swarm определяет, что желаемое состояние не совпадает с действительным, и запускает экземпляр глобального контейнера на этом узле.
Ограничения
Для демонстрации ограничений я использовал докер машину, чтобы ускорить новую машину с помощью engine label.
Затем я добавил ее в swarm.
Далее я создал сервис, ссылающийся на это ограничение.
Помните, я говорил, что сервисы являются декларативными? 😉 Это означает, что, когда мы масштабируем этот сервис, он запоминает наши ограничения и масштабирует только отвечающие условиям узлы.
John Zaccone
Docker Captain и Software Engineer в Ippon Technologies, который любит вбрасывать вещи на рынок побыстрее. Специализируется на agile, микросервисах, контейнерах, автоматизации, REST, devops.
ИТ База знаний
Полезно
— Онлайн генератор устойчивых паролей
— Онлайн калькулятор подсетей
— Руководство администратора FreePBX на русском языке
— Руководство администратора Cisco UCM/CME на русском языке
— Руководство администратора по Linux/Unix
Навигация
Серверные решения
Телефония
FreePBX и Asterisk
Настройка программных телефонов
Корпоративные сети
Протоколы и стандарты
Установка и настройка Docker Swarm
кластеризация, такая кластеризация
В этой статье мы рассмотрим процесс установки и настройки режима Docker Swarm на сервере Ubuntu 16.04.
Онлайн курс по Linux
Мы собрали концентрат самых востребованных знаний, которые позволят тебе начать карьеру администратора Linux, расширить текущие знания и сделать уверенный шаг к DevOps

Docker Swarm является стандартным инструментом кластеризации для Docker, преобразующий набор хостов Docker в один последовательный кластер, называемый Swarm. Docker Swarm обеспечивает доступность и высокую производительность работы, равномерно распределяя ее по хостингам Docker внутри кластера.

Установка Docker Swarm:
Перед началом обновите Ваш системный репозиторий до последней версии с помощью следующей команды:
После обновления следует выполнить перезагрузку системы. Необходимо еще установить среду Docker. По умолчанию Docker не доступен в репозитории Ubuntu 16.04, поэтому сначала необходимо создать хранилище Docker и начать установку с помощью следующей команды:
Добавляем GPG ключ для Docker:
Добавляем репозиторий Docker и обновляем с помощью команды:
Установка среды Docker с помощью следующей команды:
После установки запустите службу Docker во время загрузки с помощью следующей команды:
Для запуска Docker необходимы root права, а для других юзеров доступ получается только с помощью sudo. При необходимости запустить docker без использования sudo, есть возможность создать Unix и включить в него необходимых пользователей за счет выполнения следующих строк кода:
Затем выйдя из системы, делаем вход через dockeruser.
Затем перезагрузите брандмауэр, включив его при загрузке
Выполните перезагрузку “Докера”:
Создавая Docker Swarm кластер, необходимо определиться с IP-адресом, за счет которого ваш узел будет действовать в качестве диспетчера:
Вы должны увидеть следующий вывод:
Проверяем его состояние:
Если все работает правильно, вы должны увидеть следующий вывод:
Проверка статуса Docker Swarm Cluster осуществляется следующим образом:
Вывод должен быть следующим:
Узел теперь настроен правильно, пришло время добавить его в Swarm Cluster. Сначала скопируйте вывод команды «swarm init» из вывода результата выше, а затем вставьте этот вывод в рабочий узел для присоединения к Swarm Cluster:
Вы должны увидеть следующий вывод:
Теперь выполните следующую команду для вывода списка рабочего узла:
Вы должны увидеть информацию следующего вида:
Docker Swarm Cluster запущен и работает, теперь можно запустить веб-сервис в Docker Swarm Mode. За счет следующей строки кода выполнится развертывание службы веб-сервера:
Приведенная выше строка создаст контейнер веб-сервера Apache и сопоставит его с 80 портом, позволив иметь полный доступ к необходимому веб-серверу Apache из удаленной системы. Теперь запускаем проверку работающего сервиса с помощью команды:
Вы должны увидеть следующий вывод:
Запустите службу масштабирования веб-сервера с помощью строки:
А также проверьте состояние с помощью команды:
Вы должны увидеть следующий вывод:
Веб-сервер Apache работает. Теперь вы можете получить доступ к веб-серверу:

Служба веб-сервера Apache теперь распределена по двум узлам. Docker Swarm обеспечивает доступность вашего сервиса. Если веб-сервер отключается на рабочем узле, то новый контейнер будет запущен на узле менеджера. Для проверки доступности следует остановить службу Docker на рабочем узле:
Запустите службу веб-сервера с помощью команды:
Вы должны увидеть следующую информацию:
С помощью данной статьи, вы смогли установить и настроить кластер Docker Swarm для ОС Ubuntu 16.04. Теперь вы можете легко масштабировать свое приложение в кластере до тысячи узлов и пятидесяти тысяч контейнеров без существенной потери производительности.
Свой облачный хостинг за 5 минут. Часть 1: Ansible, Docker, Docker Swarm

Привет Хабр! Последние 1.5 года я работал над своим проектом, которому был необходим надежный облачный хостинг. До этого момента я больше 10 лет занимался веб-программированием и когда я решил построить свой хостинг у меня были относительно поверхностные знания в этой области, я и сейчас не являюсь системным администратором. Все что я буду рассказывать может выполнить обычный программист в течение 5 минут, просто запустив набор сценариев для Ansible, которые я подготовил специально для вас и выложил на GitHub.
Моя цель – дать вам список инструментов и общее понимание, что бы вы знали от чего отталкиваться, если у вас появится необходимость в собственном облачном хостинге. При выборе используемых инструментов я ориентировался на простоту, качество документации и стабильность. Прежде, чем использовать все это у себя в продакшене, вам определенно стоит проконсультироваться с системным администратором (я использую некоторые компоненты, которые находятся в статусе «BETA» (июнь 2015)).
Содержание
Зачем свой хостинг?
Основная причина — я хотел получить необходимый опыт. Я все больше отхожу от программирования и занимаюсь административными вопросами. Хорошему предпринимателю надо пройти весь путь самому и поработать, по возможности, на всех должностях, что бы понять как все устроено, как этим управлять, от каких людей и что требовать, как оценить их работу и их самих.
Вторая причина заключается в специфике моего проекта, он связан с приватностью персональных данных. У меня нет причин кому-то просто доверять свои данные, а своих пользователей тем-более. Меня очень волнует этот вопрос, и я обеспокоен тем, что ему уделяется так мало внимания.
Последняя причина в целях и ориентирах у стартапа в Российских реалиях. Здесь основная цель – начать зарабатывать деньги и выйти в плюс. Нет прибыли – нет стартапа, есть убыточное хобби. Поэтому, третья причина – это стоимость. У меня сейчас
5Tb данных, которые я регулярно обрабатываю, обходится мне все это
100$/месяц (можете посчитать сколько это будет стоить на AWS). Я знаю, что в следующем месяце у меня будет такая же стоимость, а проект я строю на свои деньги.
Подготовка
Первое, что необходимо сделать – раздобыть 3 сервера в одном датацентре (они должны находится как можно ближе друг к другу, что бы ping между ними был минимальный). Не имеет значения, будут это виртуальные выделенные сервера (на время тестирования) или настоящие и у какого провайдера вы их арендуете. Я заказал у DigitalOcean, выбрал установку Debian 8.1 x64 и указал добавить свой SSH ключ:
Установка закончена и у нас в распоряжении 3 «голых» сервера:
Ansible
Как вы уже поняли, мы будем использовать Ansible для конфигурирования наших серверов. Если вы не знаете что это такое и как этим пользоваться, то на Хабре есть ответы на эти вопросы:
Ansible не единственная система управления конфигурациями (есть Puppet, Chef, Salt и т.д.), так почему именно она?
Как я написал выше, один из приоритетов при выборе инструментов – простота. На управляемые машины не надо устанавливать клиенты (все работает через SSH), язык сценариев предельно прост, у проекта свежая и подробная документация, а код модулей написан на Python (что для нас преимущество, потому что Python является основным языком в стартапе).
Вообще для меня простота является признаком глубокого понимания предмета. Если один человек (знакомый с предметом), не может объяснить другому человеку (с предметом не знакомому), как он работает, значит он сам до конца не понимает этот предмет.
Это хорошо раскрыто в книге Стива Возняка – «Cтив Джобс и Я», там отец начинает рассказывать принципы электротехники Стиву, когда он еще не достиг четырех лет (книга будет интересна всем инженерам, даже если вас не интересует история Apple).
На этом этапе Ansible должен быть установлен на вашей клиентской машине (инструкция). Мне, на OS X 10.9, для этого понадобилось выполнить всего 2 команды:
Проверяем, что все ок:
Docker
Это, без сомнения, один из лучших инструментов с которыми я познакомился за последние несколько лет. Именно Docker будет сердцем нашего облачного хостинга, наделяя его по-настоящему большими возможностями.
«Из коробки» мы получаем доступ к огромному количеству готовых образов, которые мы сможем моментально выполнить в нашем облаке. У нас появляется возможность изолированно запускать необходимые сервисы разных версий одновременно, для тестирования совместимости или удовлетворения зависимостей наших веб-приложений.
Мы можем запустить 20 контейнеров с 1-ой версией нашего веб-приложения, 2 контейнера со 2-ой версией и распределив между ними нагрузку, показать новую версию только
10% посетителей, оценив стабильность работы и отзывы пользователей.
Сейчас вам необходимо установить Docker на клиентскую машину, он понадобится нам для управления будущим кластером Docker’ов. Самый простой способ сделать это – скачать GUI клиент Kitematic (доступен для Mac OS X 10.9+ и Windows 7+ 64-bit), зайти в главное меню и выбрав «Install Docker Commands» установить консольные комманды Docker’а.
Альтернативные варианты установки вы можете узнать из официальной документации (она хорошо написана и своевременно обновляется). Убедиться, что все в порядке, можно следующим образом:
Docker Swarm
Наконец-то мы дошли до самого интересного, до того, что придаст нашему хостингу «облачности». Странно, но я не нашел никакой информации о Docker Swarm на Хабре.
Docker Swarm служит для объединения множества Docker хостов в один виртуальный хост и делает это элегантно. Docker Swarm предоставляет REST API интерфейс, совместимый с Docker API. Таким образом, все инструменты, которые работают с API Docker’a (клиент Docker’a, Dokku, Compose, Krane, Flynn, Deis, DockerUI, Shipyard, Drone, Jenkins и т.д.), смогут работать с Docker Swarm, не подозревая о том, что за ним стоит кластер Docker’ов, а не одна машина.
Давайте уже построим наше облако и на практике посмотрим на что способен Docker Swarm.
Приступаем
К этому моменту у вас на клиентской машине должен быть установлен Ansible и Docker. В наличии должно быть 3 сервера с авторизацией по ключу и Debian 8.1 x64 на борту (вы можете использовать любой другой дистрибутив, внеся небольшие изменения в сценарии). Я подготовил набор сценариев для Ansible, которые сделают всю работу за вас, поэтому вам не понадобится много времени.
Скачиваем набор сценариев или клонируем репозиторий:
Открываем файл stage и заменяем в нем IP адреса на IP своих серверов:
Для того, что бы Docker Swarm мог соединяться с нодами Docker’a, они должны быть доступны снаружи (по умолчанию на 2375-ом порту для HTTP и на 2376-ом для HTTPS). Также нам надо сделать доступным снаружи и Docker Swarm Manager, что бы мы могли управлять кластером. HTTP нам для этих целей не подходит (мы же строим облако для себя, а не любого интернет-пользователя), остаётся HTTPS, а точнее TLS (подробнее можно почитать в официальной документации).
Принцип работы следующий: мы создаём свой центр сертификации (далее ЦС), подписываем сертификаты для сервера и клиента Docker’a. После этого «демон» докера принимает соединения от клиентов, сертификат которых подписан тем же ЦС, что и сертификат «демона». Клиент Docker’а выполняет такую же проверку и подключается только к тем серверам Docker’a, сертификат которых подписан тем же ЦС. Docker Swarm Manager использует такую же схему. Таким образом обеспечивается аутентификация и безопасность нашего мини-облака.
Единственное, что вам требуется сделать, это сгенерировать ключи для вашего ЦС (все остальное выполнится в автоматическом режиме). Просто выполните следующие команды из корневой директории проекта (пароль, который вы укажите, необходимо запомнить, он нам понадобится) и заполните ответы на вопросы (тут нет никаких конкретный требований, домен можете указать любой):
Осталось заполнить значения некоторых переменных в файле:
Переменная certs.ca.password должна содержать пароль, который мы указали, когда генерировали приватный ключ для нашего центра сертификации.
Переменная docker_swarm.token должна содержать идентификатор нашего будущего кластера, который можно сгенерировать следующей командой:
Переменная docker_swarm.manager должна содержать IP адрес хоста, где будет запущен Docker Swarm Manager (укажите IP адрес любого из ваших серверов).
В сценариях Ansible указано, что необходимо создать пользователя support, добавить его в группу sudo и запретить root‘у возможность авторизации по SSH. Значение переменной ssh.users[].password должно быть хешем пароля для указанного выше пользователя. Для того, что бы его получить, необходимо выполнить следующую команду на любой Linux машине (можете зайти на один из ваших серверов по SSH и выполнить ее):
Значение ssh.users[].key должно быть вашим публичным ключом, который по умолчанию находится тут
Пример заполненного файла конфигурации можете глянуть ниже:
Теперь мы готовы приступить к построению долгожданного облака:
Из-за того, что мы отключили возможность авторизации root‘ом, а также добавили пользователя support (это прописано в сценариях Ansible), все последующие запуски надо выполнять с флагами -s (sudo) и -K (для запроса пароля для sudo):
Проверка и использование
Мы готовы к проверке нашего новоиспеченного облака:
Ура! Я почти дописал эту большую статью, а вы успешно закончили построение своего облака.
Если у вас появится необходимость, то вы можете подключаться к любому из Docker хостов отдельно:
Но мы же не для этого прошли весь этот путь, правда? Давайте попробуем запустить несколько экземпляров Nginx в нашем облаке:
Проверяем:
Давайте попробуем запустить еще 2 экземпляра Nginx:
Как мы видим 3-ий экземпляр запустился, а вот 4-ый нет: FATA[0001] Error response from daemon: unable to find a node with port 80 available. Docker Swarm Scheduler видит, что нет хостов со свободным 80-ым портом.
Мы можем посмотреть, какие контейнеры сейчас выполняются у нас в кластере и удостовериться, что каждая копия Nginx была запущена на разной машине:
Возможности Docker Swarm на этом не заканчиваются, а только начинаются (об этом можно почитать тут и тут).
Как я писал в начале статьи, моя цель – дать вам список инструментов и общее понимание, что бы вы знали от чего отталкиваться и я надеюсь, что она достигнута.
В следующей части я расскажу, что такое Service Discovery, как распределять нагрузку в нашем облаке и какие для этого есть инструменты.
На этом все. Всем спасибо за внимание. Стабильных вам облаков и удачи!
Подписывайтесь на меня в Twitter, я рассказываю о работе в стартапе, своих ошибках и правильных решениях, о python и всём, что касается веб-разработки.
Краткое введение в Docker Swarm mode
Docker — прекрасен. С ним можно упаковать приложение по контейнерам, забросить их на случайный хост, и всё будет просто работать. Но на одном хосте особо не отмасштабируешься. Да и если хост прикажет долго жить, всё приложение отправится на тот свет вместе с ним. Конечно, для масштабирования можно завести сразу несколько хостов, объединить их при помощи overlay сети, так что и места больше будет, и возможность для контейнеров общаться останется.
Но опять же, как всем этим управлять? Хосты всё ещё могут отмирать. Как быстро определить, какой именно? Какие контейнеры на нём были? Куда теперь их переносить?
Начиная с версии 1.12.0 Docker может работать в режиме Swarm («Рой». В старых версиях был просто Docker Swarm, но тот работал по-другому), и потому способен решать все эти проблемы самостоятельно.
Что такое режим Swarm
Docker в Swarm режиме это просто Docker Engine, работающий в кластере. Кроме того, что он считает все кластерные хосты единым контейнерным пространством, он получает в нагрузку несколько новых команд (вроде docker node и docker service ) и концепцию сервисов.
Сервисы — это ещё один уровень абстракции над контейнерами. Как и у контейнера, у сервиса будет имя, базовый образ, опубликованные порты и тома (volumes). В отличие от контейнера, сервису можно задать требования к хосту (constraints), на которых его можно запускать. Да и вообще, сервис можно масштабировать прямо в момент создания, указав, сколько именно контейнеров для него нужно запустить.
Но важно понимать одну большую разницу. Сама по себе команда docker service create не создаёт никаких контейнеров. Она описывает желаемое состояние сервиса, а дальше уже Swarm менеджер будет искать способы это состояние достигнуть. Найдёт подходящие хосты, запустит контейнеры, будет следить, чтобы с ними (и хостами под ними) всё было хорошо, и перезапустит контейнер, если «хорошо» закончится. Иногда желаемое состояние сервиса так и не будет достигнуто. Например, если в кластере закончились доступные хосты. В таком случае сервис будет висеть в режиме ожидания до тех пор, пока что-нибудь не изменится.
План на сегодня
Будем играться. Пользы от абстрактной и непонятной теории — ноль, так что создадим-ка свой собственный уютный Docker кластер на три виртуальные машины. Запустим в нём один сервис для визуализации кластера, и ещё один, например web, чтобы масштабировался и заодно демонстрировал, как он успешно восстанавливается от внезапно упавшего хоста.
Что понадобится
Нам понадобится установленный Docker версии 1.12.0 и новее, docker-machine и VirtualBox. Первые два обычно устанавливаются вместе c Docker Toolbox на Маке и Windows. На Linux, ЕМНИП, docker-machine устанавливается отдельно, но всё ещё достаточно понятно. С установкой же VirtualBox проблем вообще не бывает. Обычно.
Я буду использовать Docker 17.03.1-ce для Mac и VirtualBox 5.1.20
Шаг 0. Создаём три виртуальные машины
Создавать машины при помощи именно docker-machine имеет смысл хотя бы потому, что они сразу будут идти с предустановленным Docker. Из трёх хостов на одном мы поселим менеджера Swarm, а на двух других — обычных рабочих. Собственно, создание виртуальных машин — удивительно безболезненное занятие:


