Как создать приложение для потоковой обработки данных при помощи Apache Flink
Среди рассматриваемых нами фреймворков для сложной обработки данных на Java есть и Apache Flink. Хотим предложить вам перевод неплохой статьи из блога Analytics Vidhya на портале Medium, чтобы оценить читательский интерес. Не стесняйтесь участвовать в голосовании!

В этой статье мы разберем «снизу вверх», как организовать потоковую обработку при помощи Flink; в облачных сервисах и на других платформах предоставляются решения для потоковой обработки (в некоторых из них «под капотом» интегрирован Flink). Если вы хотели разобраться в этой теме с азов, то нашли как раз то, что искали.
Наше монолитное решение не справлялось с возрастающими объемами входящих данных; следовательно, его требовалось развивать. Настало время перейти к новому поколению в эволюции нашего продукта. Было решено воспользоваться потоковой обработкой. Это новая парадигма поглощения данных, более выигрышная по сравнению с традиционной пакетной обработкой данных.
Apache Flink: краткая характеристика
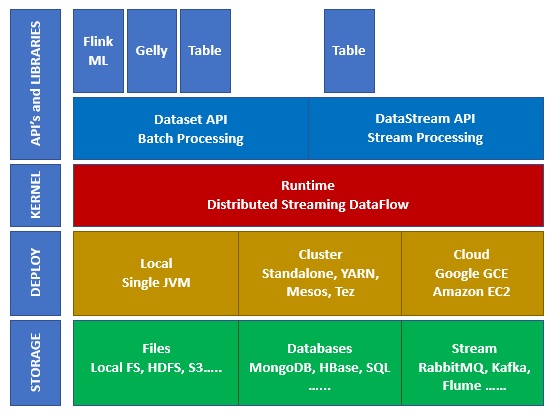
Apache Flink – это фреймворк для масштабируемой распределенной обработки потоков, предназначенный для операций над непрерывными потоками данных. В рамках этого фреймворка используются такие концепции как источники, преобразования потоков, параллельная обработка, планирование, присваивание ресурсов. Поддерживаются разнообразные места назначения данных. В частности, Apache Flink может подключаться к HDFS, Kafka, Amazon Kinesis, RabbitMQ и Cassandra.
Flink известен своей высокой пропускной способностью и малыми задержками, поддерживает согласованную строго однократную обработку (все данные обрабатываются по одному разу, без дублирования), а также высокую доступность. Как и любой другой успешный опенсорсный продукт, Flink обладает обширным сообществом, в котором культивируются и расширяются возможности этого фреймворка.
Flink может обрабатывать потоки данных (размер потока является неопределенным) или множества данных (размер множества данных является определенным). В этой статье рассматривается именно обработка потоков (обращение с объектами DataStream ).
Потоковая обработка и присущие ей вызовы
В настоящее время, при повсеместной распространенности устройств «Интернета Вещей» и прочих сенсоров, данные непрерывно поступают из множества источников. Такой нескончаемый поток данных требует адаптировать к новым условиям традиционные пакетные вычисления.
Flink реализует согласованную строго однократную обработку, что гарантирует точность вычислений, а разработчику не требуется для этого ничего специально программировать.
Из чего состоят пакеты Flink
Сток данных
Одна из основных целей Flink, наряду с преобразованием данных, заключается в управлении потоками и направлении их в те или иные места назначения. Эти места называются «стоками». В Flink есть встроенные стоки (текст, CSV, сокет), а также представляемые «из коробки» механизмы для подключения к иным системам, например, Apache Kafka.
Метки событий Flink Event
При обработке потоков данных исключительно важен фактор времени. Существует три способа определить временную метку:
Недостаток, возникающий при использовании времени обработки существенен в распределенных и асинхронных окружениях, поскольку это не детерминистический метод. Метки времени, которыми сопровождаются события потока, могут рассинхронизироваться, если между ходом машинных часов есть разница; сетевая задержка также может привести к запаздыванию во времени, когда событие ушло с одной машины и прибыло на другую.
Поскольку не сам Flink устанавливает метку времени, должен быть механизм, который просигнализирует, должно быть обработано это событие или нет; данный механизм называется «водяной знак» (watermark). Тема водяных знаков выходит за рамки данной статьи; подробнее об этом можно почитать в документации по Flink.
Время поглощения не подходит для обработки событий, приходящих вне очереди, либо опоздавших данных, поскольку метка времени ставится, когда поглощение начинается; этим оно отличается от времени события, в котором предусмотрена возможность выявлять отложенные события и обрабатывать их, опираясь на механизм водяных знаков.
Подробнее о временных метках и о том, как они влияют на потоковую обработку, можно почитать по следующей ссылке.
Разбивка на окна
Поток по определению бесконечен; следовательно, механизм обработки связан с определением фрагментов (например, периодов-окон). Таким образом поток разбивается на партии, удобные для агрегации и анализа. Определение окна – это операция над объектом DataStream или каким-то другим, который его наследует.
Есть несколько видов окон, зависящих от времени:
Кувыркающееся окно (конфигурация по умолчанию):
Поток делится на окна эквивалентного размера, которые не перекрываются друг с другом. Пока поток течет, Flink непрерывно производит вычисления над данными на основе такой фиксированной во времени раскадровки.
Такие окна могут перекрываться друг с другом, а свойства скользящего окна определяются размером данного окна и отступом (когда начинать следующее окно). В таком случае в конкретный момент времени могут обрабатываться события, относящиеся более чем к одному окну.
Скользящее окно
А вот как оно выглядит в коде:
Включает все события, ограниченные рамками одного сеанса. Сеанс завершается при отсутствии активности, или если по истечении определенного временного периода не зафиксировано никаких событий. Данный период может быть фиксированным или динамическим, в зависимости от обрабатываемых событий. Теоретически, если промежуток между сеансами меньше размера окна, то сеанс может никогда не закончиться.
В первом фрагменте кода ниже показан сеанс с фиксированной временной величиной (2 секунды). Второй пример реализует динамическое сеансовое окно, на основе событий потока.
Вся система трактуется как единственное окно.
Flink также позволяет реализовывать собственные окна, логику которых определяет пользователь.
Кроме окон, зависящих от времени, есть и другие, например, Окно счета, где устанавливается предельное количество входящих событий; по достижении порога X, Flink обрабатывает X событий.
Окно счета для трех событий
После теоретического введения давайте подробнее обсудим, что представляет собой поток данных с практической точки зрения. Подробнее об Apache Flink и потоковых процессах рассказано на официальном сайте.
Описание потока
В качестве резюме теоретической части на следующей блок-схеме показаны основные потоки данных, реализованные в сниппетах кода из этой статьи. Поток, изображенный ниже, начинается из источника (файлы записываются в каталог) и продолжается при обработке событий, превращаемых в объекты.
Реализация, изображенная ниже, состоит из двух путей обработки. Тот, что показан в верхней части разделяет один поток на два боковых потока, а затем объединяет их, получая поток третьего типа. Сценарий, изображенный в нижней части схемы, описывает обработку потока, после которой результаты работы передаются в сток.
Далее попытаемся пощупать руками практическую реализацию вышеизложенной теории; весь исходный код, рассматриваемый далее, выложен на GitHub.
Базовая обработка потоков (пример #1)
Усвоить концепции Flink будет проще, если начать с простейшего приложения. В этом приложении продьюсер записывает файлы в каталог, таким образом имитируется поток информации. Flink считывает файлы из этого каталога и записывает обобщенную информацию по ним в каталог назначения; это и есть сток.
Далее давайте внимательно посмотрим, что происходит при обработке:
Преобразование сырых данных в объект:
В приведенном ниже фрагменте кода потоковый объект ( InputData ) преобразуется в кортеж строки и целого числа. Он извлекает лишь определенные поля из потока объектов, группируя их по одному полю квантами по две секунды.
Создание точки назначения для потока (реализация стока данных):
Образец кода, описывающего создание стока данных.
Расщепление потоков (пример #2)
Функция ProcessFunction собирает определенные объекты (на основе критерия) и отправляет в главный выводной коллектор (заключается в SingleOutputStreamOperator ), а остальные события передаются в боковые выводы. Поток DataStream разделяется по вертикали и публикует различные форматы для каждого бокового потока.
Обратите внимание: определение бокового потока вывода основано на уникальном теге вывода (объект OutputTag ).
Пример кода, демонстрирующий, как разделить поток
Объединение потоков (пример #3)
Последняя операция, которая будет рассмотрена в этой статье – объединение потоков. Идея заключается в том, чтобы скомбинировать два разных потока, форматы данных в которых могут отличаться, из которых собрать один поток с унифицированной структурой данных. В отличие от операции объединения из SQL, где слияние данных происходит по горизонтали, объединение потоков осуществляется по вертикали, поскольку поток событий продолжается и никак не ограничен во времени.
Объединение потоков выполняется путем вызова метода connect, после чего для каждого элемента в каждом отдельном потоке определяется операция отображения. В результате получается объединенный поток.
Листинг, демонстрирующий получение объединенного потока
Создание рабочего проекта
Итак, резюмируем: демо-проект загружен на GitHub. Там описано, как его собрать и скомпилировать. Это хорошая отправная точка, чтобы поупражняться с Flink.
Выводы
В этой статье описаны основные операции, позволяющие создать рабочее приложение для обработки потоков на основе Flink. Цель приложения – дать общее представление о важнейших вызовах, присущих потоковой обработке, и заложить базис для последующего создания полнофункционального приложения Flink.
Поскольку у потоковой обработки множество аспектов, и она сопряжена с разными сложностями, многие вопросы в этой статье остались не раскрыты; в частности, выполнение Flink и управление задачами, использование водяных знаков при установке времени для потоковых событий, подсадка состояния в события потока, выполнение итераций потока, выполнение SQL-подобных запросов к потокам и многое другое.
Надеемся, этой статьи было достаточно, чтобы вам захотелось попробовать Flink.
Apache flink что такое
Apache Flink – это распределенная отказоустойчивая платформа обработки информации с открытым исходным кодом, используемая в высоконагруженных Big Data приложениях для анализа данных, хранящихся в кластерах Hadoop. Разработанный в 2010 году в Техническом университете Берлина в качестве альтернативы Hadoop MapReduce для распределенных вычислений больших наборов данных, Flink использует подход ориентированного графа, устраняя необходимость в отображении и сокращения [1].
Подобно Apache Spark, Flink имеет готовые коннекторы с Apache Kafka, Amazon Kinesis, HDFS, Cassandra, Google Cloud Platform и др., а также интегрируется со всеми основными системами управления кластерами: Hadoop YARN, Apache Mesos и Kubernetes. Кроме того, Флинк может использоваться в качестве основы автономного кластера [1].
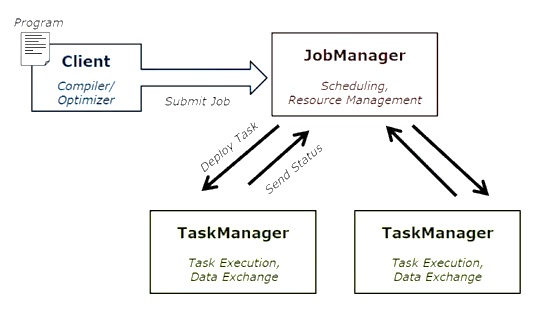
Как устроен Apache Flink: архитектура и принцип работы
Входные данные каждого потока Флинк берутся с одного или нескольких источников, например, из очереди сообщений Apache Kafka, СУБД HBase или файловой системы Hadoop HDFS, отправляясь в один или несколько приемников (очередь сообщений, файловую систему или базу данных). В потоке может быть выполнено произвольное число преобразований. Эти потоки могут быть организованы как ориентированный ациклический граф, позволяющий приложению распределять и объединять потоки данных. Помимо потоковой обработки Big Data в рамках DataStream API, Flink также позволяет работать с пакетами данных с помощью мощного DataSet API.
При развертывании приложения Flink автоматически идентифицирует требуемые ресурсы на основе настроенного параллелизма приложения и запрашивает их из системы управления кластером. В случае сбоя Flink заменяет контейнер, запрашивая новые ресурсы. Отправка и управление приложением происходит через REST. Это облегчает интеграцию Flink в различных средах [1].
Подобно другому популярному фреймворку потоковой обработки Big Data, Apache Spark, Флинк содержит оптимизатор и библиотеки для машинного обучения, аналитических графиков и реляционной обработки данных.
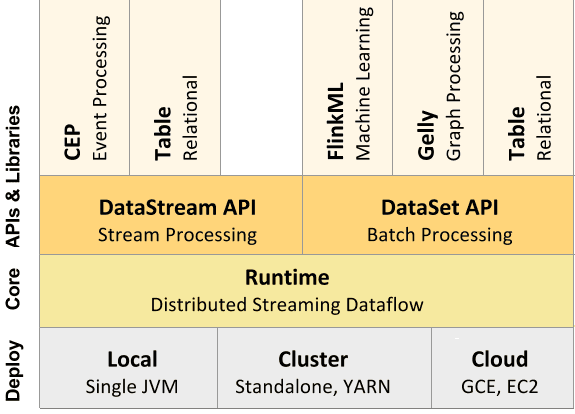 Архитектура Apache Flink
Архитектура Apache Flink
Преимущества и недостатки Флинк
Ключевыми достоинствами Apache Flink можно назвать следующие [1]:
При всех вышеперечисленных достоинствах, для Флинк характерны следующие недостатки:
Сравнению Flink с Apache Spark, другим популярным фреймворком потоковой обработки больших данных мы посвятили отдельную статью.
Apache Flink — Краткое руководство
Прогресс данных за последние 10 лет был огромным; это породило термин «большие данные». Не существует фиксированного размера данных, который вы можете назвать большими данными; любые данные, которые ваша традиционная система (RDBMS) не может обработать, — это большие данные. Эти Большие Данные могут быть в структурированном, полуструктурированном или неструктурированном формате. Первоначально в данных было три измерения — объем, скорость, разнообразие. Размеры теперь вышли за пределы только трех. Теперь мы добавили другие Vs — Veracity, Validity, Vulnerability, Value, Variable и т. Д.
Большие данные привели к появлению множества инструментов и платформ, которые помогают в хранении и обработке данных. Существует несколько популярных сред больших данных, таких как Hadoop, Spark, Hive, Pig, Storm и Zookeeper. Это также дало возможность создавать продукты Next Gen в нескольких областях, таких как здравоохранение, финансы, розничная торговля, электронная коммерция и многое другое.
Будь то MNC или стартап, каждый использует большие данные для их хранения, обработки и принятия более разумных решений.
Apache Flink — пакетная обработка в режиме реального времени
С точки зрения больших данных, существует два типа обработки:
Обработка, основанная на данных, собранных во времени, называется пакетной обработкой. Например, менеджер банка хочет обработать данные за последний месяц (собранные за определенное время), чтобы узнать количество чеков, которые были отменены за последний 1 месяц.
Обработка, основанная на непосредственных данных для мгновенного результата, называется обработкой в реальном времени. Например, менеджер банка получает предупреждение о мошенничестве сразу после совершения мошеннической операции (мгновенный результат).
В приведенной ниже таблице перечислены различия между пакетной обработкой и обработкой в реальном времени.
| Пакетная обработка | Обработка в реальном времени |
|---|---|