Тест производительности с помощью AIDA64
AIDA64 имеет множество тестов, которые возможно применять для оценивания состояния разных составляющих компьютера или техники в целом. Это искусственные тесты, т.е. они позволят дать оценку предельной эффективности системы. Тесты позволят узнать пропускную эффективность памяти, ЦП и других элементов базируются на специальном механизме AIDA64, обеспечивающий около 740 синхронных потоков работы и 10 категорий вычислителей. Этот способ гарантирует абсолютную реализацию для мультипроцессоров.

AIDA64 представляет ещё одиночные тесты для оценивания пропускной способности обработки, редактирования и изменения, и удержание кэша ЦП и памяти компьютера. Дополнительно есть другой тестовый узел для оценивания эффективности девайсов памяти, флеш карт и жестких дисков.
Как пользоваться тестом
Это тестовая панель, чтобы на нее перейти необходимо нажать на кнопку в меню Сервис | Тест GPGPU, эта панель предоставляет коллекцию тестов OpenCL GPGPU. С помощью них проводят диагностику производительности с применением разнообразных нагрузок OpenCL. Любой дополнительно полученного теста следует осуществлять на 16-ти графических процессорах, или же их соединять. В общем эта опция предназначена замерять уровень эффективности самого различного компьютерного оборудования.

Тестирование уровня производительности памяти
Эти тесты предоставляют характеристику наибольшей пропускной способности при исполнении подобных целей, таких как редактирование и удаление. Помимо этого, этот тест предоставляет функцию которая может просчитать приостановку памяти, что случается из-за использования процессора сведений памяти. Задержка памяти показывает промежуток времени, на протяжении которого производится перенос информации в регистре цельно численной арифметических данных процессора.
Тест CPU Queen
Этот немудреный тест дает оценку, каким способом происходит функционирование по предсказанию разветвлений основного ЦП и выполняется неверный прогноз ответвления. Делается выработка заключений для головоломки с 8 ферзями, находящимися на шахматной доске 10х10. Обдумываем систему: если частота равна, тот ЦП, который имеет самый низкий конвейер и если у него низкий уровень затрат, тот и выдаст лучшие итоги диагностики.

CPU PhotoWorxx
Данный тест может рассчитать продуктивность процессора на базе алгоритмов работы двухмерных изображений. С достаточно большими RGB творится такое:
CPU ZLib
Представленный тест выполняет замер эффективности основного ЦП и подсистемы оперативной памяти применяя сжатие объемов информации ZLib. Указания используются базовые x86, но содействие гиперпотока, мультипроцессоры (SMP) и многоядерность (CMP).
CPU AES
Тест дает оценку эффективность основного ЦП с применением шифровки по AES (методу зашифровки по узлам). В данный момент AES применяют в некоторых программах: 7z, RAR, WinZip. Указания к применению: x86, MMX и SSE4.1. Функция на аппаратном уровне разгонен на вычислителях VIA C3, C7, Nano и QuadCore, с методами содействия VIA PadLock Security Engine. Подходит и для цп со списком директив Intel AES-NI. Производится обеспечение гиперпотоковости, мультипроцессоры (SMP) и многоядерности (CMP).
CPU Hash
Данный тест замеряет эффективность основного ЦП применяя методы кэширования SHA1 в соотношении с основным шаблоном работы 180-4. Кодировка сделана с использованием ассемблер и основан под базовые ядра AMD, Intel и VIA учитывая внедрение комплекта директив SSE2, SSSE3, MMX, MMX+/SSE, AVX, AVX2, XOP, BMI.
FPU VP8
Представленный тест делает испытание с применением видео кодека Google VP8. Выполняется кодирование за 1 путь, располагающего увеличение 1280×720 и воспроизводящиеся со быстротой 8192 кбит/с (с учётом предельного качества). Элементы снимков производятся при содействии модуля фракталов Жюлиа FPU. В этом деле используется другие продолжения и наборы директив: MMX, SSE2, SSSE3 или SSE4.1.
Видео
Тестирование производительности
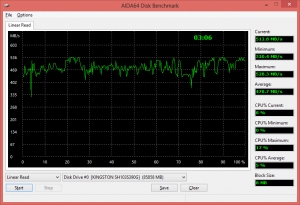
Система AIDA64 даёт возможность за счёт отдельных тестов проводить оценку пропускной способности считывания, записи, копирования и торможения кэша. Ко всему этому прилагается модуль-тест, позволяющий оценить работу накопительных устройств, в частности жестких дисков (S)ATA или SCSI, SSD-накопителей, RAID-массивов, карт памяти, оптических дисков, и USB-накопителей.
Тестирование качества работы GPGPU
Эта тестовая панели располагает набором тестов OpenCL GPGPU. Доступ к этой функции вы можете получить в разделе Сервис/Тест GPGPU. Благодаря им оценивают вычислительную производительность с использованием различных нагрузок OpenCL. Каждый отдельно взятый тест можно проходить на 16-ти графических процессорах, в том числе процессорах NVIDIA, AMD и Intel, или же их комбинировать. Несомненно, идёт полная поддержка конфигураций CrossFire, SLI, APU и dGPU. В целом такая функция позволяет определить уровень производительности любой вычислительной техники, предоставленной в качестве графического процессора устройств OpenCL.

AIDA64 проводит не только комплексные тесты, но и микротесты, которые есть в разделах «Тесты»/ «Страница». За счёт полной базы данных показатели можно сравнивать с аналогичными по другим конфигурациям.
Тестирование уровня производительности памяти
Кроме того, тест позволяет оценить задержку памяти, что происходит из-за считывания процессором данных из памяти системы. Задержка памяти являет собой время, на протяжении которого идёт передача данных в регистре целочисленной арифметики процессора после того, как происходит выдачи команды для считывания.
Целочисленный тест CPU Queen

CPU PhotoWorxx

Представленный целочисленный тест даёт возможность установить производительность процессора на основе алгоритмов обработки двухмерных фото. С довольно крупными изображение RGB происходит следующее:
CPU ZLib
Предложенный целочисленный тест даёт комбинированную оценку производительности главного процессора и подсистемы памяти благодаря сжатию данных ZLib. Инструкции применяются основные x86, но поддержка гиперпотока, мультипроцессоры (SMP) и многоядерность (CMP).
CPU AES
Представленный целочисленный тест оценивает производительность главного процессора при выполнении шифровки по криптоалгоритму AES (симметричному алгоритму шифрования по блокам). На сегодня AES используют в нескольких инструментах сжатия: 7z, RAR, WinZip. Применяют и в программных шифровках TrueCrypt, BitLocker, FileVault (Mac OS X). Инструкции следующие: x86, MMX и SSE4.1. Система аппаратно ускорена на процессорах VIA C3, C7, Nano и QuadCore, с технологиями поддержки VIA PadLock Security Engine. Применима и для процессора с набором команд Intel AES-NI. Идёт поддержка гиперпотоковости, мультипроцессоры (SMP) и многоядерности (CMP).
CPU Hash
FPU VP8
Данный тест проводит анализ сжатия видео кодеком Google VP8 (WebM) по версии 1.1.0. Осуществляется кодировка за 1 проход видеопотока, имеющего расширение 1280×720 и идущего со скоростью 8192 кбит/с ( с учётом максимально настроенного качества). Составляющие кадров генерируются при помощи модуля фракталов Жюлиа FPU. Здесь применяется следующие расширения и наборы команд: MMX, SSE2, SSSE3 или SSE4.1. Тут также поддерживается мультипроцессоры (SMP), многоядерность (CMP) и гиперпотоковость.
FPU Julia

При помощи этого теста оценивают производительность операций одинарной точности (с плавающей частотой для 32-битной системы). Происходит вычисление нескольких кусочков фрактала Жюлиа. Используют тот же язык, подходит под ядра AMD, Intel и VIA с использованием таких наборов команд: x87, 3DNow!, 3DNow!+, SSE, AVX, AVX2, FMA и FMA4. Поддержка аналогичная.
FPU Mandel

Операции двойной точности с плавающей запятой для 64-битной точности тестируют при помощи FPUMandel. Осуществляется моделирование частей фрактала Мандельброта. Язык тот же, процессоры такие же, поддержка, как и в предыдущих тестах. Набор команд: FMA и FMA4, x87, SSE2, AVX, AVX2,
FPU SinJulia

Сравнение производительности различных архитектур CPU по тестам AIDA64
реклама
Многие сталкиваются с проблемами выбора комплектующих для ПК. И одной из них является неочевидность разницы в производительности различных поколений процессоров, ведь не только всё зависит от частоты и количества ядер. В сети множество различных тестов и сравнений, но часто можно натолкнуться на рекламу или просто не понять всей картины, что было до и после, в случае выбора не самой новой архитектуры. Чтобы внести какую-то степень ясности в этот вопрос, сравним производительность популярных архитектур за последние 10 лет.
Методика сравнения
Одним из решений для показательного сравнения различных микроархитектур является AIDA64, а именно все тесты, кроме тестов памяти, CPU Queen и CPU PhotoWorxx, потому что данные тесты не линейны и зависят от используемой памяти. Остальные тесты линейные, не зависят от используемой памяти, их результаты кратны количеству ядер и поэтому повторяемые. Погрешность обычно составляет не более 2%. Также все тесты будут производиться с выключенной HyperThreading.
AMD K10 (45nm)
реклама
Phenom II X6 1100T (релиз декабрь 2010) является флагманом данной микроархитектуры. Socket AM3, шесть ядер, 125W TDP и частота 3.30GHz. Поддержка DDR3-1600. Отличается от современников отсутствием инструкций SSSE3, SSE4.1, SSE4.2, AES, AVX, AVX2, FMA3.
AMD Piledriver (32nm)
FX-8350 (релиз октябрь 2012) заявлен как самый производительный процессор данной микроархитектуры с TDP 125W. Однако не все материнские платы, рассчитанные на Socket AM3+ и поддерживающие 125W K10-процессоры, поддерживают данный процессор официально, и в прошлой статье мы узнали почему это так. Новый техпроцесс, восемь ядер на борту и частота аж в 4.00GHz. Поддержку памяти расширили до стандарта DDR3-1866. Добавили инструкции SSSE3, SSE4.1, SSE4.2, AES, AVX, FMA3. Теперь мы можем оценить результаты сравнения производительности на ядро K10 и Piledriver.
В левом столбце частота K10, необходимая для достижения результата Piledriver, работающего на частоте 4.00GHz. В правом столбце аналогично по отношению к K10.
реклама
Как видно, FX лидирует только в тесте AES, практически 10-кратное увеличение производительности, видимо из-за наличия соответствующей инструкции. Также видно, что более высокая частота на самом деле на 20% кукурузная (3.96/3.30) и в целочисленных операциях ядро Piledriver на частоте 4.00GHz равно ядру K10 на частоте 3.30GHz. Но в тестах FPU наглядно виден регресс по сравнению с поколением K10. Из плюсов только восемь таких ядер, против шести. Сравним данный шедевр процессоростроения с Intel Sandy Bridge, которая явилась на свет за полтора года до AMD Piledriver.
Intel Sandy Bridge (32nm)
Intel для настольных ПК делает процессоры похолоднее. Core i7-2600K (релиз январь 2011) с частотой 3.40GHz и 95W TDP, LGA 1155. четыре ядра. Поддерживает DDR3-1333. Стоит отметить, что у Intel иначе устроен TurboBoost, т.е. базовая частота относительно заявленного TDP является скорее промежуточной, и в данной модели турбо-частота 3.50GHz по всем ядрам (в некоторых моделях встречается и более значительная разница между базовой и турбо частотами). Тем не менее будем проводить тесты с отключенным турбо-режимом. Сравним Intel Sandy Bridge с AMD Piledriver.
Полный разгром. В операциях FPU у Piledriver вообще всё плохо, в 2,5 раза медленнее. Даже восемь ядер, не догонят четырёх, значительно более быстрых. В целочисленных же операциях отставание у Piledriver в 1,2 раза. А ведь i7-2600K может даже 3.50GHz при TDP 95W, в отличие от FX-8350, которому и 125W мало для сохранения своих 4.00GHz.
реклама
Intel Ivy Bridge (22nm)
В целом производительность осталась той же, наблюдается лишь небольшой прирост в целочисленных операциях и SHA3.
Intel Haswell (22nm)
Значительный прирост во многих сценариях.
Intel Broadwell (14nm)
Наблюдается снижение производительности в некоторых AVX-операциях. Проверял несколько раз. Отпишитесь в комментариях, у всех ли так. Очень мало было выпущено моделей для сегмента настольных ПК. Также нет заметной разницы по энергопотреблению в сравнении с Haswell (22nm).
Intel Skylake (14nm)
Небольшой прирост в целочисленных операциях и значительный в AVX.
Intel Kaby Lake (14nm)
Всё в рамках погрешностей в измерении. Архитектурно изменений нет. Но несмотря на те же 14нм, инженеры увеличили частоты при том же уровне TDP.
Intel Coffee Lake (14nm)
Вновь никакой разницы в производительности на такт. Значительные улучшения в техпроцессе, и как следствие повышение частот и количества ядер.
Intel Comet Lake (14nm)
И вновь нет роста производительности на такт. Зато как совершенствуют 14нм техпроцесс… Архитектурно тот же Skylake, который при 65W TDP имел четыре ядра и частоту 3.70GHz, и Comet Lake, у которого при том же TDP восемь ядер по 4.60GHz.
AMD Zen (14nm)
По основным тестам (CPU ZLib, FPU Julia/Mandel) эти архитектуры весьма близки.
AMD Zen+ (12nm)
По сравнению с Zen видно небольшое увеличение производительности на такт во всех сценариях. Также практически незаметное увеличение энергоэффективности, несмотря на переход на 12нм.
AMD Zen 2 (7nm)
Значительный рост производительности на такт. За исключением небольшого отставания в целочисленных операциях, AMD Zen 2 обогнала актуальную архитектуру от Intel. Но всё же по энергоэффективности лидирует 14нм Intel, например немногим ранее выпущенный Core i7-9700KF, работающий в турбо на частоте 4.60GHz по всем восьми ядрам и потребляющий 95W.
Пишите в комментариях, если у вас не согласуются результаты, с полученными мною. Также приветствуется критика и пожелания. Всем добра ^-^
Что означают тесты в AIDA64

Что на самом деле означают тесты в AIDA64
Многим из вас, скорее всего, знакома популярная программа AIDA64. Когда-то она именовалась Everest, но что тогда, что сейчас, программа занимает лидирующие позиции в анализе комплектующих персонального компьютера, тесте его производительности и стабильности.
В комплекте программы есть набор тестов, которые позволяют пользователям оценить, насколько из компьютер силен и могуч.
Вот мне и стало интерестно, что же на самом деле скрывается за замысловатыми названиями тестов и какую сторону производительности ПК каждый из тестов отображает.
Тестирование производительности кэша и дисков
Тестирование производительности GPGPU
Следующая тестовая панель, доступ к которой можно получить в разделе меню Сервис | Тест GPGPU, предлагает набор комплексных тестов производительности OpenCL GPGPU. Они разработаны для оценки вычислительной производительности GPGPU при помощи различных нагрузок OpenCL. Каждый отдельный тест можно выполнить максимум на 16 графических процессорах, включая процессоры AMD, Intel и NVIDIA, или их комбинации. Конечно же, полностью поддерживаются конфигурации CrossFire и SLI, а также dGPU и APU. В общем, данная функция позволяет протестировать производительность практически любого вычислительного устройства, которое представлено как графический процессор среди устройств OpenCL.
Тестирование производительности памяти
Тесты производительности памяти оценивают максимально возможную пропускную способность при выполнении определенных операций (чтение, запись, копирование). Они написаны на языке ассемблера и максимально оптимизированы для всех популярных вариантов ядер процессоров AMD, Intel и VIA путем применения соответствующих расширений набора команд x86/x64, x87, MMX, MMX+, 3DNow!, SSE, SSE2, SSE4.1, AVX и AVX2. Тест задержки памяти оценивает типичную задержку при считывании центральным процессором данных из системной памяти. Задержка памяти — это время для предоставления данных в регистре целочисленной арифметики центрального процессора после выдачи команды считывания.
CPU Queen
Этот простой целочисленный тест оценивает возможности предсказания ветвлений центрального процессора и ошибочного прогнозирования ветви. Он вычисляет решения для классической головоломки с восемью ферзями, размещенными на шахматной доске 10х10. Теоретически, при одинаковой тактовой частоте, процессор с более коротким конвейером и меньшими накладными расходами в случае ошибочного предположения о ветвлении может показать более высокие результаты теста. Например, если отключить гиперпотоковость, процессоры Pentium 4 на базе Intel Northwood получат более высокие баллы, чем центральные процессоры Intel Prescott, поскольку в первых присутствует 20-ступенчатый конвейер, а в последних — 31-ступенчатый. CPU Queen использует целочисленные оптимизации MMX, SSE2 и SSSE3.
CPU PhotoWorxx
Данный целочисленный тест оценивает производительность центрального процессора при помощи нескольких алгоритмов обработки двухмерных фотографий. Он выполняет следующие задачи c довольно крупных RGB-изображениях:
Тест, в основном, предназначен для блоков выполнения операций целочисленной арифметики SIMD-архитектуры центрального процессора и подсистем памяти. Тест CPU PhotoWorxx использует соответствующие расширения наборов команд x87, MMX, MMX+, 3DNow!, 3DNow!+, SSE, SSE2, SSSE3, SSE4.1, SSE4A, AVX, AVX2, и поддерживает NUMA, гиперпотоковость, мультипроцессоры (SMP) и многоядерность (CMP).
CPU ZLib
Данный целочисленный тест оценивает комбинированную производительность центрального процессора и подсистемы памяти при помощи свободной библиотеки для сжатия данных ZLib. ЦП ZLib использует только основные инструкции x86, но поддерживает гиперпотоковость, мультипроцессоры (SMP) и многоядерность (CMP).
CPU AES
Этот целочисленный тест оценивает производительность центрального процессора при выполнении шифрования по криптоалгоритму AES. В шифровании AES — это симметричный алгоритм блочного шифрования. Сегодня AES используется в нескольких инструментах сжатия, таких как 7z, RAR, WinZip, а также в программах шифрования BitLocker, FileVault (Mac OS X), TrueCrypt. CPU AES использует соответствующие инструкции x86, MMX и SSE4.1, он является аппаратно ускоренным на процессорах VIA C3, VIA C7, VIA Nano и VIA QuadCore, поддерживающих технологию VIA PadLock Security Engine, а также на процессорах, поддерживающих расширение наборов команд Intel AES-NI. Данный тест поддерживает гиперпотоковость, мультипроцессоры (SMP) и многоядерность (CMP).
CPU Hash
Этот целочисленный тест оценивает производительность центрального процессора при выполнении алгоритма кэширования SHA1 согласно Федеральному стандарту обработки информации 180-4. Код для этого теста написан на языке ассемблера, он оптимизирован для большинства популярных вариантов ядер процессоров AMD, Intel и VIA путем применения соответствующих расширений набора команд MMX, MMX+/SSE, SSE2, SSSE3, AVX, AVX2, XOP, BMI и BMI2. Тест CPU Hash является аппаратно ускоренным на процессорах VIA C7, VIA Nano и VIA QuadCore, поддерживающих технологию VIA PadLock Security Engine.
FPU VP8
Этот тест измеряет производительность сжатия видео кодеком Google VP8 (WebM) версии 1.1.0. Происходит кодирование за 1 проход видеопотока с разрешением 1280×720 («HD ready ») и скоростью 8192 кбит/с при максимальных настройках качества. Содержимое кадров генерируется модулем фракталов Жюлиа FPU. Программный код теста использует расширения и наборы команд MMX, SSE2, SSSE3 или SSE4.1, а также поддерживает гиперпотоковость, мультипроцессоры (SMP) и многоядерность (CMP).
FPU Julia
Этот тест оценивает производительность в операциях одинарной точности с плавающей запятой (32-битная точность) посредством вычислений нескольких фрагментов фрактала Жюлиа. Код для этого теста написан на языке ассемблера, он оптимизирован для большинства популярных вариантов ядер процессоров AMD, Intel и VIA путем применения соответствующих расширений набора команд x87, 3DNow!, 3DNow!+, SSE, AVX, AVX2, FMA и FMA4. FPU Julia поддерживает гиперпотоковость, мультипроцессоры (SMP) и многоядерность (CMP).
FPU Mandel
Этот тест оценивает производительность в операциях двойной точности с плавающей запятой (64-битная точность) путем моделирования нескольких фрагментов фрактала Мандельброта. Код для этого теста написан на языке ассемблера, он оптимизирован для большинства популярных вариантов ядер процессоров AMD, Intel и VIA путем применения соответствующих расширений набора команд x87, SSE2, AVX, AVX2, FMA и FMA4. FPU Mandel поддерживает гиперпотоковость, мультипроцессоры (SMP) и многоядерность (CMP).
FPU SinJulia
Тест оценивает производительность в операциях повышенной точности с плавающей запятой (80-битная точность) посредством вычислений по каждому отдельному кадру с использованием модифицированного фрактала Жюлиа. Код для этого теста написан на языке ассемблера, он оптимизирован для большинства популярных вариантов ядер процессоров AMD, Intel и VIA, позволяет использовать тригонометрические и экспоненциальные инструкции архитектуры x87. FPU SinJulia поддерживает гиперпотоковость, мультипроцессоры (SMP) и многоядерность (CMP).
Ну вот теперь хотя бы немного стало понятнее, что означает количество «попугаев» в том или ином тесте в AIDA64.
Обновил свой старый ноутбук с i3-2310M на i7-2820QM и показываю, что получилось
В этом материале вы познакомитесь с историей интересного апгрейда пожилого, но не сдающегося ноутбука Toshiba Satellite C670-13E.
реклама
На этом сокете G2 также выходили процессоры 3ххх поколения, но они не смогут работать на старом чипсете, а именно H65. Кроме того при выборе процессора стоит учитывать, когда выходили оригинальный и замещающий процессор, потому что более новый процессор может не заработать на старом БИОСе. 2820QM и 2310M вышли одновременно, так что проблем быть не должно. Можно рискнуть, и взять более новый процессор, все в ваших руках.
Для ноутбука компания производитель изготовила всего одну единственную версию БИОС, и больше уже новых не будет. Поэтому есть мало шансов, на поддержку более свежих процессоров.
Взамен одной планки памяти на четыре гигабайта было решено установить две по восемь и на частоте 1600МГц.
реклама
Память прекрасно работает на платформе Intel, несмотря на то что предназначена для платформы AMD.
При установке «нового» процессора Intel Core i7-2820QM память сразу же заработала на частоте 1,6 ГГц. Вручную изменить частоту памяти нельзя – в БИОС нет никаких настроек памяти.
Приступим к тестам.
Здесь три изображения из программы AIDA64. Слева направо: система в заводском состоянии, система со стоковым процессором и двумя планками памяти, система с новым процессором и памятью.
Как видно на скриншоте, замена памяти сразу положительно сказалась на скорости работы ноутбука из-за включения двухканального режима работы памяти. Установка нового центрального CPU еще больше подняла уровень производительности памяти и кэша. Частота процессорного кэша всех уровней многократно выше у нового процессора, по сравнению со старым.
Перейдем к стандартным тестам AIDA64.
Тест CPU Queen показал прирост на 130%.
реклама
Увеличение производительности получилось на грани погрешности, потому что имеющаяся в ноутбуке дискретная видеокарта GeForce 315M никак не изменилась, и заменить другим видеочипом ее нельзя. Малозаметный прирост вызван подъемом общей скорости работы аппарата. На этом видео ускорителе с удовольствием (чтобы счетчик кадров показывал свыше 60 кадров в секунду) можно поиграть только, например, в такие легендарные игры как GTA: San Andreas, Morrowind, первая Mafia.
Помимо прочего, было решено удалить привод для дисков, ибо в современном мире это атавизм. Вместо привода было решено установить родной жесткий диск Hitachi при помощи салазок, а на место диска установить SSD объемом 500 ГБ от Samsung 860.


