Git для новичков (часть 2)
В прошлой статье, я рассказал, что такое Git, как его установить и выложить свой код на GitHub. Сегодня мы поговорим про работу в команде над одним проектом. И как это устроено в Git.
В данной статье, вся работа с Git будет через командную строку.
Совместная работа

Для того, чтобы создать новую ветку вводим:
Эти команды делают тоже самое, только второй вариант позволяет сразу переключиться в новую ветку. Вносить изменения в новую ветку можно сразу после ее создания.
При создании новой ветки, старайтесь называть ее кратким и ёмким именем. Чтобы сразу было понятно, что именно изменялось по проекту. Если вы используете, какую-нибудь систему для ведения задач, то можете в начале названия ветки указывать ID задачи, чтобы можно было легко найти, на основе какой задачи была создана ветка. Например вот так:
В каждом новом commit следует оставлять коммент и в нем описывать суть изменений.
Переключаться между ветками можно такой командой:
Для того чтобы посмотреть текущее состояние ветки, например, какие файлы добавлены или не добавлены для создания commit, можно выполнить команду:
Теперь все ваши изменения, в ветке master улетели в GitHub. Таким же образом, можно отправить любую другую ветку:
?Совет. Каждый коммит, лучше заливать сразу в удаленный репозиторий. Никто не застрахован, поломки собственного ПК. Поэтому чтобы не потерять все наработки, не забывайте сливать ваши изменения на GitHub.
Как же теперь другой человек получит все ваши изменения?
Для этого вам понадобиться GitHub или любой другой сервис для хранения кода. В прошлой статье я рассказывал как отправить код в GitHub. Сейчас я покажу, как его скопировать обратно себе на компьютер.
Если у вашего друга раньше не было проекта, то ему придется его «клонировать» себе:
? Адрес репозитория на GitHub можно получить, нажав на зеленую кнопку Code
После выполнения команды, в папке где появиться проект и ваш друг сможет с ним работать. Все ветки и их история также подтянуться.
Теперь самое главное
Перед тем, как создавать новый функционал и новую ветку, стоит обновить master на вашем устройстве. Для этого нужно находиться в этой ветке и выполнить следующую команду:
Таким же образом можно актуализировать любую другую ветку, заменив название ветки master на вашу.
Для обновления всех веток сразу, можно использовать такую, команду, но не рекомендую:
Теперь можно создавать новую ветку и кодить.
Какие проблемы могут возникнуть?
Git старается автоматически сливать изменения, однако это не всегда возможно. Иногда возникают конфликты. Например, когда в двух ветках были изменения в одной и той же строчке кода. Если такое произошло, то необходимо разрешить конфликт вручную. Для этого откройте файл там, где этого произошло. Например, вы можете увидеть что-то подобное:
После внесения нужных изменений добавьте ваш файл через git add как измененный и создайте новый commit:
Вспомогательные команды
Просмотреть изменения относительно двух веток можно командой:
Удалить ненужную ветку:
Просмотр историю ветки:
Подсказки по популярным командам:
Практика и вспомогательные инструменты
Для улучшения ваших навыков, в очередной раз оставлю ссылку на полезный тренажер с заданиями.
Так же, для удобства использования в Visual Studio Code, советую поставить это расширение, которое визуализирует ваши ветки и commit, и помогает с ними работать.
Инструкция: заливаем проект на GitHub без командной строки
Загружаем проект в удалённый репозиторий через GitHub Desktop


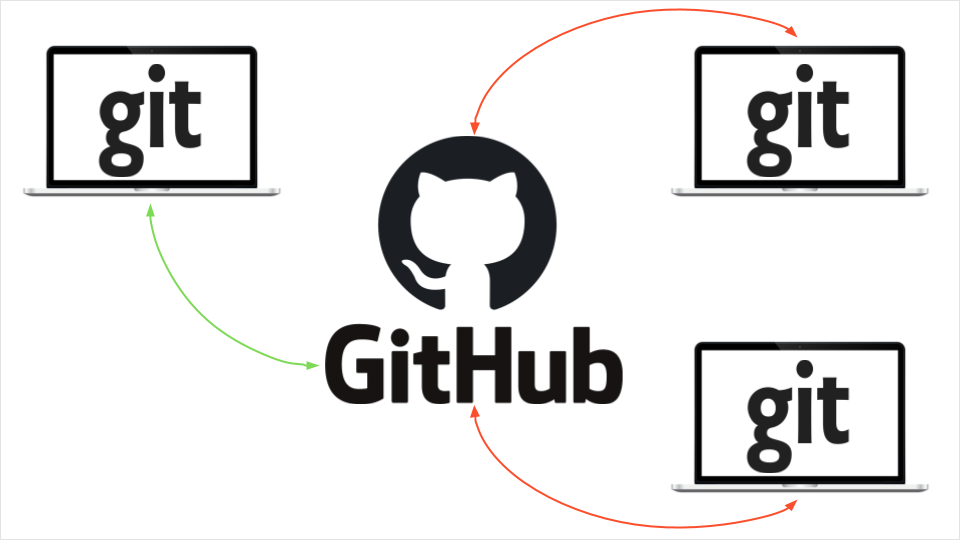
GitHub — это облачный сервис, где разработчики хранят файлы и совместно работают над проектами. GitHub взаимодействует с системой контроля версий Git. Сегодня вы узнаете, как он работает. Мы создадим репозиторий, добавим в него файлы проекта, синхронизируем репозиторий с ПК, научимся обновлять файлы, добавлять новые ветки и сливать их в одну.
Для работы понадобится GitHub Desktop — приложение от GitHub, которое позволяет выполнять необходимые действия без командной строки. Эта статья предполагает, что вы знаете про контроль версий Git. Если нет — рекомендуем почитать об этом, а затем возвращаться к изучению GitHub.

Автор статей о программировании. Изучает Python, разбирает сложные термины и объясняет их на пальцах новичкам. Если что-то непонятно — возможно, вы еще не прочли его следующую публикацию.
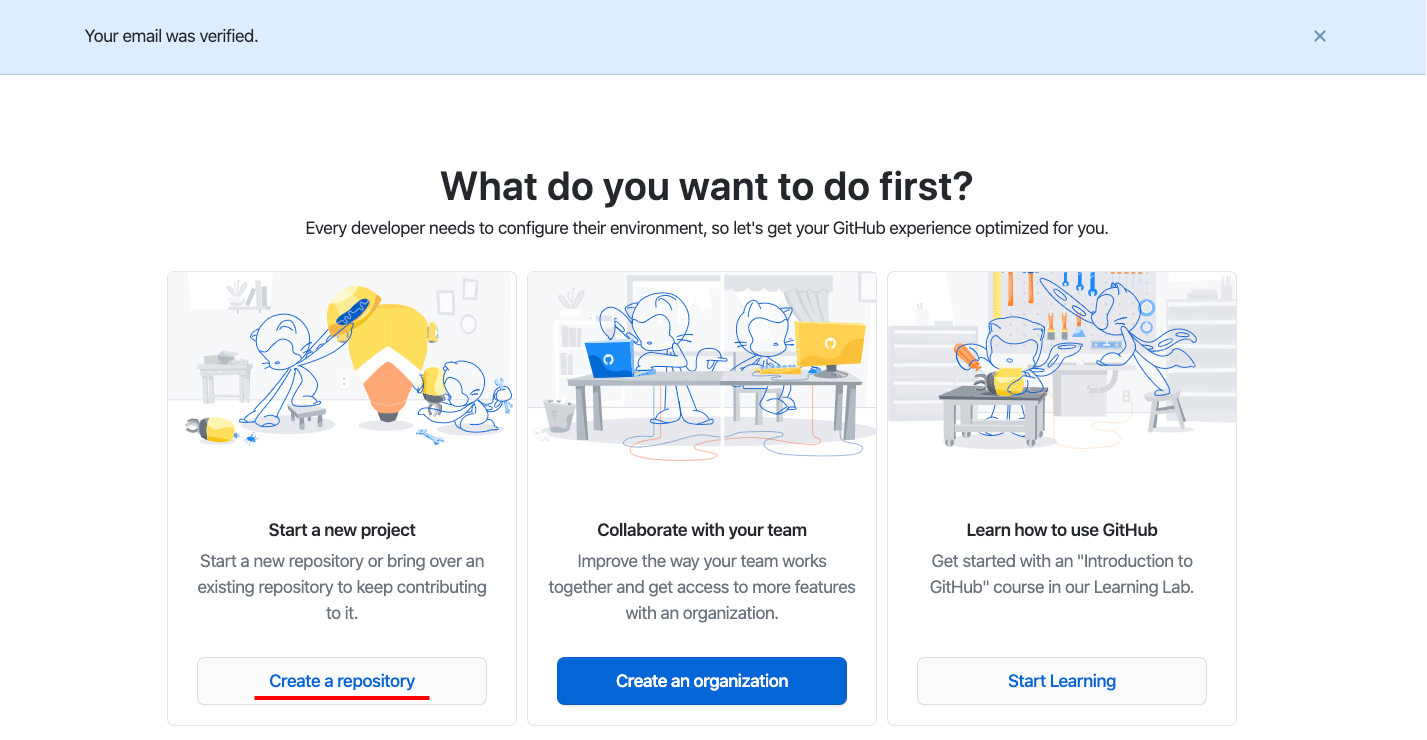
1. Создаём учётную запись
Перейдите на сайт github.com, зарегистрируйтесь и верифицируйте адрес электронной почты. Выберите тип аккаунта: публичный или приватный. В публичном аккаунте репозитории видны всем, а в приватном — только тем участникам, которым вы сами открыли доступ. По умолчанию вы переходите на бесплатный тариф, который можно изменить в разделе Pricing. Платные тарифы отличаются повышенной безопасностью, размером хранилища и некоторыми специальными опциями для профессиональной разработки.
Далее рекомендуем выставить настройки безопасности и заполнить профиль — на GitHub много IT-рекрутеров, которые по информации в профиле набирают кандидатов в проекты. Поставьте фото и ссылки на соцсети, откройте доступ к электронной почте и напишите о себе: расскажите про опыт, специализацию, пройденные курсы, рабочий стек технологий и выполненные проекты. Заполненный профиль повышает вероятность трудоустройства.
2. Добавляем удалённый репозиторий
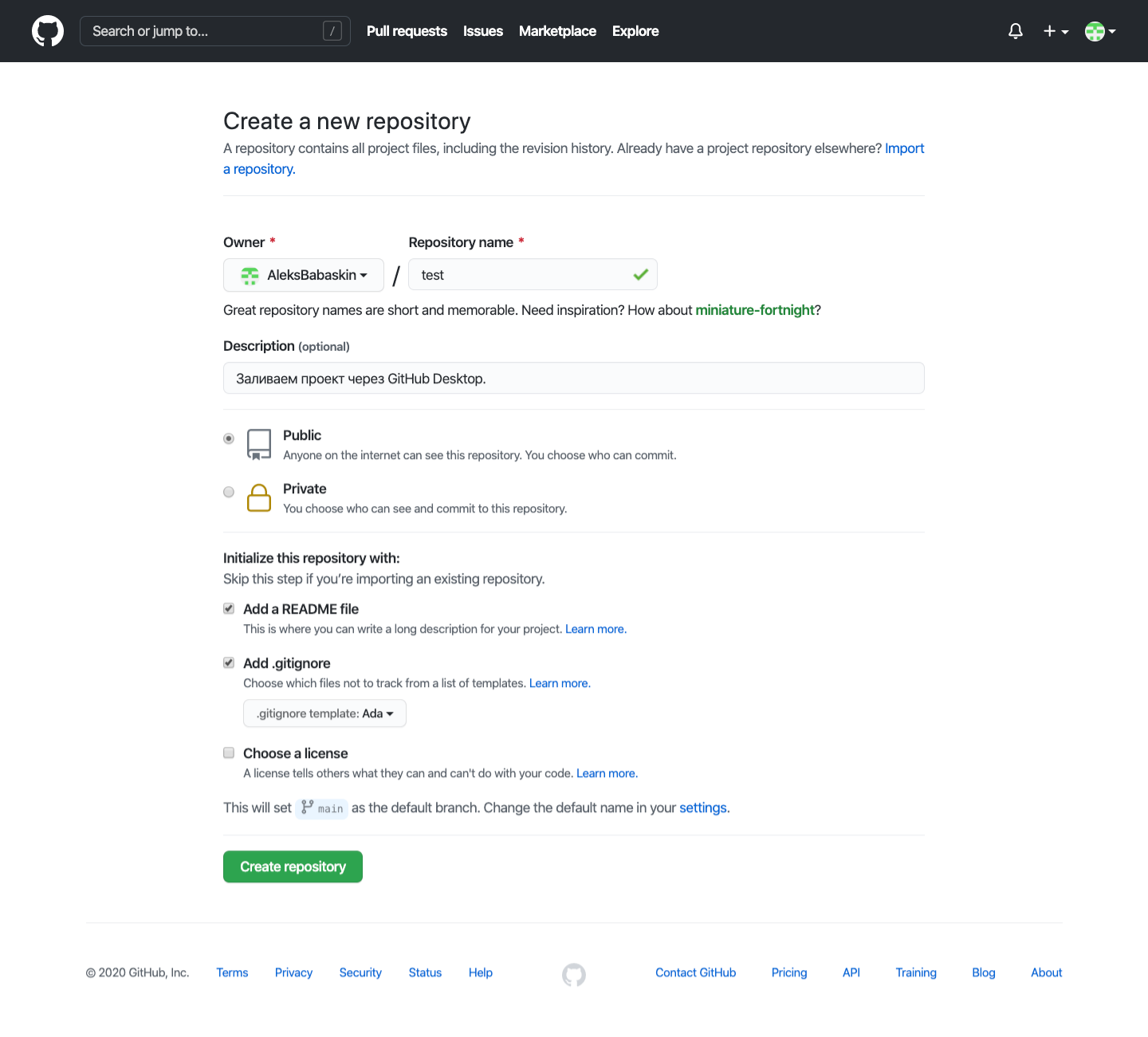
Репозиторий — это файловое хранилище проектов. На бесплатном тарифе можно загружать до 500 МБ данных и создавать неограниченное количество репозиториев.
Чтобы создать репозиторий, нажмите на кнопку New repository, назовите проект и кликните Create repository. Можно добавить описание проекта, сделать его публичным или приватным и прикрепить технические файлы:
Мы создаём тестовый репозиторий, поэтому обойдёмся без лицензии — выберем только два дополнительных файла: README file и gitignore. Если вы пока не знаете, что писать в README file и что добавлять в gitignore, — оставьте эти файлы пустыми или посмотрите инструкцию в разделе Read the guide.
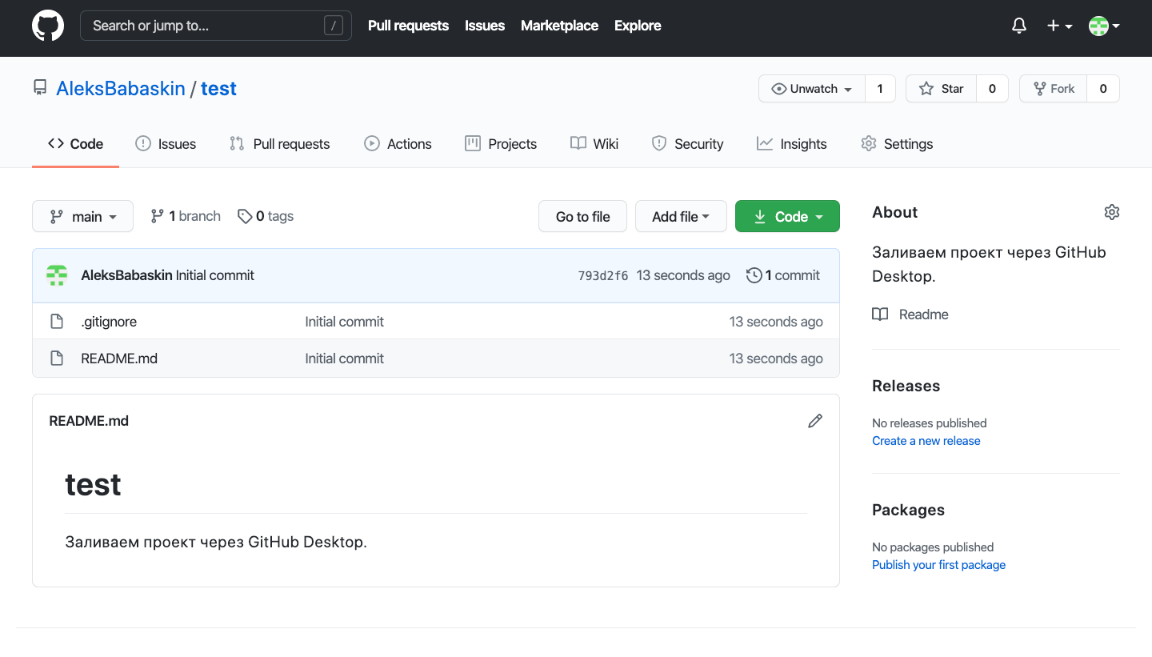
В README file отображается краткое описание проекта — сейчас этот файл не важен, поэтому мы не будем менять его описание. Изменим файл gitignore и сделаем так, чтобы он не учитывал служебные папки операционной системы:
После редактирования gitignore делаем коммит — записываем в историю проекта факт того, что мы установили ограничение для файлов Mac OS.
Работа с удалёнными репозиториями
Для того, чтобы внести вклад в какой-либо Git-проект, вам необходимо уметь работать с удалёнными репозиториями. Удалённые репозитории представляют собой версии вашего проекта, сохранённые в интернете или ещё где-то в сети. У вас может быть несколько удалённых репозиториев, каждый из которых может быть доступен для чтения или для чтения-записи. Взаимодействие с другими пользователями предполагает управление удалёнными репозиториями, а также отправку и получение данных из них. Управление репозиториями включает в себя как умение добавлять новые, так и умение удалять устаревшие репозитории, а также умение управлять различными удалёнными ветками, объявлять их отслеживаемыми или нет и так далее. В данном разделе мы рассмотрим некоторые из этих навыков.
Вполне возможно, что удалённый репозиторий будет находиться на том же компьютере, на котором работаете вы. Слово «удалённый» не означает, что репозиторий обязательно должен быть где-то в сети или Интернет, а значит только — где-то ещё. Работа с таким удалённым репозиторием подразумевает выполнение стандартных операций отправки и получения, как и с любым другим удалённым репозиторием.
Просмотр удалённых репозиториев
Если у вас больше одного удалённого репозитория, команда выведет их все. Например, для репозитория с несколькими настроенными удалёнными репозиториями в случае совместной работы нескольких пользователей, вывод команды может выглядеть примерно так:
Это означает, что мы можем легко получить изменения от любого из этих пользователей. Возможно, что некоторые из репозиториев доступны для записи и в них можно отправлять свои изменения, хотя вывод команды не даёт никакой информации о правах доступа.
Обратите внимание на разнообразие протоколов, используемых при указании адреса удалённого репозитория; подробнее мы рассмотрим протоколы в разделе Установка Git на сервер главы 4.
Добавление удалённых репозиториев
В предыдущих разделах мы уже упоминали и приводили примеры добавления удалённых репозиториев, сейчас рассмотрим эту операцию подробнее. Для того, чтобы добавить удалённый репозиторий и присвоить ему имя (shortname), просто выполните команду git remote add :
Получение изменений из удалённого репозитория — Fetch и Pull
Как вы только что узнали, для получения данных из удалённых проектов, следует выполнить:
Данная команда связывается с указанным удалённым проектом и забирает все те данные проекта, которых у вас ещё нет. После того как вы выполнили команду, у вас должны появиться ссылки на все ветки из этого удалённого проекта, которые вы можете просмотреть или слить в любой момент.
Когда вы клонируете репозиторий, команда clone автоматически добавляет этот удалённый репозиторий под именем «origin». Таким образом, git fetch origin извлекает все наработки, отправленные на этот сервер после того, как вы его клонировали (или получили изменения с помощью fetch). Важно отметить, что команда git fetch забирает данные в ваш локальный репозиторий, но не сливает их с какими-либо вашими наработками и не модифицирует то, над чем вы работаете в данный момент. Вам необходимо вручную слить эти данные с вашими, когда вы будете готовы.
Начиная с версии 2.27, команда git pull выдаёт предупреждение, если настройка pull.rebase не установлена. Git будет выводить это предупреждение каждый раз пока настройка не будет установлена.
Отправка изменений в удаленный репозиторий (Push)
Когда вы хотите поделиться своими наработками, вам необходимо отправить их в удалённый репозиторий. Команда для этого действия простая: git push
. Чтобы отправить вашу ветку master на сервер origin (повторимся, что клонирование обычно настраивает оба этих имени автоматически), вы можете выполнить следующую команду для отправки ваших коммитов:
Просмотр удаленного репозитория
Это был пример для простой ситуации и вы наверняка встречались с чем-то подобным. Однако, если вы используете Git более интенсивно, вы можете увидеть гораздо большее количество информации от git remote show :
Удаление и переименование удалённых репозиториев
Если по какой-то причине вы хотите удалить удаленный репозиторий — вы сменили сервер или больше не используете определённое зеркало, или кто-то перестал вносить изменения — вы можете использовать git remote rm :
При удалении ссылки на удалённый репозиторий все отслеживаемые ветки и настройки, связанные с этим репозиторием, так же будут удалены.
Git для новичков (часть 1)
Что такое Git и зачем он нужен?
С помощью Git-a вы можете откатить свой проект до более старой версии, сравнивать, анализировать или сливать свои изменения в репозиторий.
Репозиторием называют хранилище вашего кода и историю его изменений. Git работает локально и все ваши репозитории хранятся в определенных папках на жестком диске.
Так же ваши репозитории можно хранить и в интернете. Обычно для этого используют три сервиса:
Как работает
В итоге получается очень простой граф, состоящий из одной ветки ( main ) и четырех commit. Все это может превратиться в более сложный граф, состоящий из нескольких веток, которые сливаются в одну.
Об этом мы поговорим в следующих статьях. Для начала разберем работу с одной веткой.
Установка
Основой интерфейс для работы с Git-ом является консоль/терминал. Это не совсем удобно, тем более для новичков, поэтому предлагаю поставить дополнительную программу с графическим интерфейсом (кнопками, графиками и т.д.). О них я расскажу чуть позже.
Но для начала, все же установим сам Git.
Windows. Проходим по этой ссылке, выбираем под вашу ОС (32 или 64 битную), скачиваем и устанавливаем.
Для Mac OS. Открываем терминал и пишем:
Linux. Открываем терминал и вводим следующую команду.
Настройка
Вы установили себе Git и можете им пользоваться. Давайте теперь его настроим, чтобы когда вы создавали commit, указывался автор, кто его создал.
Открываем терминал (Linux и MacOS) или консоль (Windows) и вводим следующие команды.
Создание репозитория
Теперь вы готовы к работе с Git локально на компьютере.
Создадим наш первый репозиторий. Для этого пройдите в папку вашего проекта.
Теперь Git отслеживает изменения файлов вашего проекта. Но, так как вы только создали репозиторий в нем нет вашего кода. Для этого необходимо создать commit.
Отлично. Вы создали свой первый репозиторий и заполнили его первым commit.
Процесс работы с Git
Не стоит после каждого изменения файла делать commit. Чаще всего их создают, когда:
Создан новый функционал
Добавлен новый блок на верстке
Исправлены ошибки по коду
Вы завершили рабочий день и хотите сохранить код
Это поможет держать вашу ветки в чистоте и порядке. Тем самым, вы будете видеть историю изменений по каждому нововведению в вашем проекте, а не по каждому файлу.
Визуальный интерфейс
Как я и говорил ранее, существуют дополнительные программы для облегчения использования Git. Некоторые текстовые редакторы или полноценные среды разработки уже включают в себя вспомогательный интерфейс для работы с ним.
Но существуют и отдельные программы по работе с Git. Могу посоветовать эти:
Я не буду рассказывать как они работают. Предлагаю разобраться с этим самостоятельно.
Создаем свой первый проект и выкладываем на GitHub
Давайте разберемся как это сделать, с помощью среды разработки Visual Studio Code (VS Code).
Перед началом предлагаю зарегистрироваться на GitHub.
Создайте папку, где будет храниться ваш проект. Если такая папка уже есть, то создавать новую не надо.
Установите себе дополнительно анализаторы кода для JavaScript и PHP
Откройте вашу папку, которую создали ранее
После этого у вас появится вот такой интерфейс
Здесь будут располагаться все файлы вашего проекта
Здесь можно работать с Git-ом
Кнопка для создания нового файла
Кнопка для создания новой папки
Давайте теперь перейдем во вкладу для работы с Git-ом.
Откроется вот такое окно:
Кнопка для публикации нашего проекта на GitHub
Вы создали и опубликовали репозиторий на GitHub.
Теперь сделаем изменения в коде и попробуем их снова опубликовать. Перейдите во вкладку с файлами, отредактируйте какой-нибудь файл, не забудьте нажать crtl+s (Windows) или cmd+s (MacOS), чтобы сохранить файл. Вернитесь обратно во вкладу управления Git.
Если посмотреть на значок вкладки Git, то можно увидеть цифру 1 в синем кружке. Она означает, сколько файлов у нас изменено и незакоммичено. Давайте его закоммитим и опубликуем:
Кнопка для просмотра изменений в файле. Необязательно нажимать, указал для справки
Добавляем наш файл для будущего commit
Отправляем наш commit в GitHub
Поздравляю, вы научились создавать commit и отправлять его в GitHub!
Это первая вводная статья по утилите Git. Здесь мы рассмотрели:
Как его устанавливать
Как его настраивать
Как инициализировать репозиторий и создать commit через консоль
Как на примере VS Code, опубликовать свой код на GitHub
Забегая вперед, советую вам погуглить, как работают следующие команды:
P.S. Для облегчения обучения, оставлю вам ссылку на бесплатный тренажер по Git.
Ежедневная работа с Git
Я совсем не долго изучаю и использую git практически везде, где только можно. Однако, за это время я успел многому научиться и хочу поделиться своим опытом с сообществом.
Конечно, я попытаюсь рассказать обо всём по-порядку, начиная с основ. Поэтому, эта статья будет крайне полезна тем, кто только начинает или хочет разобраться с git. Более опытные читатели, возможно, найдут для себя что-то новое, укажут на ошибки или поделятся советом.
Вместо плана
Очень часто, для того чтобы с чем-то начать я изучаю целую кучу материалов, а это — разные люди, разные компании, разные подходы. Всё это требует много времени на анализ и на понимание того, подойдёт ли что-нибудь мне? Позже, когда приходит понимание, что универсальное решение отсутствует, появляются совершенно другие требования к системе контроля версий и к разработке.
Окружение
Если вы открываете консоль, пишите git и получаете вот это:
Перестаём бояться экспериментировать
Строго говоря, даже неудачный git push можно исправить.
Поэтому, спокойно можете клонировать любой репозиторий и начать изучение.
Строим репозитории
В первую очередь нужно понять что такое git-репозиторий? Ответ очень прост: это набор файлов. Папка `.git`. Важно понимать, что это только набор файлов и ничего больше. Раз 20 наблюдал проблему у коллег с авторизацией в github/gitlab. Думая, что это часть git-системы, они пытались искать проблему в конфигруации git, вызывать какие-то git-команды.
В частности, при клонировании вот так:
урл «превращается» в
Т.е. используется SSH и проблемы нужно искать в нём. Как правило, это неправильно настроенный или не найденный ssh-ключ. Гуглить надо в сторону «SSH Auth Key git» или, если совсем по взрослому, проверить, что же происходит:
Какие протоколы поддерживаются поможет справка (раздел GIT URLS):
Сделаем себе один (будет нашим главным тестовым репозиторием):
Итог: у нас есть 3 репозитория. Там ничего нет, зато они готовы к работе.
Начало GIT
Скандалы! Интриги! Расследования!
Как это всё работает?
Как это всё можно понять и запомнить?
Для этого нужно заглянуть под капот. Рассмотрим всё в общих чертах.
Git. Почти под капотом
Git сохраняет в commit содержимое всех файлов (делает слепки содержимого каждого файла и сохраняет в objects). Если файл не менялся, то будет использован старый object. Таким образом, в commit в виде новых объектов попадут только изменённые файлы, что позволит хорошо экономить место на диске и даст возможность быстро переключиться на любой commit.
Это позволяет понять, почему работают вот такие вот забавные штуки:
Да, не стоит хранить «тяжёлые» файлы, бинарники и прочее без явной необходимости. Они там останутся навсегда и будут в каждом клоне репозитория.
Каждый коммит может иметь несколько коммитов-предков и несколько дочерних-коммитов:
Мы можем переходить (восстанавливать любое состояние) в любую точку этого дерева, а точнее, графа. Для этого используется git checkout:
Каждое слияние двух и более коммитов в один — это merge (объединение двух и более наборов изменений).
Каждое разветвление — это появление нескольких вариантов изменений.
Кстати, тут хочется отметить, что нельзя сделать тэг на файл/папку, на часть проекта и т.д. Состояние восстанавливается только целиком. Поэтому, рекомендуется держать проекты в отдельном репозитории, а не складывать Project1, Project2 и т.д. просто в корень.
Теперь к веткам. Выше я написал:
В Git нет веток* (с небольшой оговоркой)
Получается, что так и есть: у нас есть много коммитов, которые образуют граф. Выбираем любой путь от parent-commit к любому child-commit и получаем состояние проекта на этот коммит. Чтобы коммит «запомнить» можно создать на него именованный указатель.
Такой именованный указатель и есть ветка (branch). Так же и с тэгом (tag). `HEAD` работает по такому же принципу — показывает, где мы есть сейчас. Новые коммиты являются продолжением текущей ветки (туда же куда и смотрит HEAD).
Указатели можно свободно перемещать на любой коммит, если это не tag. Tag для того и сделан, чтобы раз и навсегда запомнить коммит и никуда не двигаться. Но его можно удалить.
Вот, пожалуй, и всё, что нужно знать из теории на первое время при работе с git. Остальные вещи должны показаться теперь более понятными.
Терминология
index — область зафиксированных изменений, т.е. всё то, что вы подготовили к сохранению в репозиторий.
commit — изменения, отправленные в репозиторий.
HEAD — указатель на commit, в котором мы находимся.
master — имя ветки по-умолчанию, это тоже указатель на определённый коммит
origin — имя удалённого репозитория по умолчанию (можно дать другое)
checkout — взять из репозитория какое-либо его состояние.
Простые правки
Если вы сделали что-то не так, запутались, не знаете, что происходит — эти две команды вам помогут.
Вернёмся к нашим репозиториям, которые создали раньше. Далее обозначу, что один разработчик работает в dev1$, а второй в dev2$.
Поделимся со всеми. Но поскольку мы клонировали пустой репозиторий, то git по умолчанию не знает в какое место добавить коммит.
Он нам это подскажет:
Второй разработчик может получить эти изменения, сделав pull:
Добавим ещё пару изменений:
Посмотрим, что же мы сделали (запускаем gitk):
Выделил первый коммит. Переходя по-порядку, снизу вверх, мы можем посмотреть как изменялся репозиторий:
До сих пор мы добавляли коммиты в конец (там где master). Но мы можем добавить ещё один вариант README.md. Причём делать мы это можем из любой точки. Вот, например, последний коммит нам не нравится и мы пробуем другой вариант. Создадим в предыдущей точке указатель-ветку. Для этого через git log или gitk узнаем commit id. Затем, создадим ветку и переключимся на неё:
Выглядит это так:
Теперь нам понятно, как создаются ветки из любой точки и как изменяется их история.
Быстрая перемотка
Наверняка, вы уже встречали слова fast-forward, rebase, merge вместе. Настало время разобраться с этими понятиями. Я использую rebase, кто-то только merge. Тем «rebase vs merge» очень много. Авторы часто пытаются убедить, что их метод лучше и удобнее. Мы пойдём другим путём: поймём, что же это такое и как оно работает. Тогда сразу станет ясно, какой вариант использовать в каком случае.
Пока, в пределах одного репозитория, сделаем ветвление: создадим файл, положим в репозиторий, из новой точки создадим два варианта файла и попробуем объединить всё в master:
Создадим файл collider.init.sh с таким содержанием:
Добавим, закоммитим и начнём разработку в новой ветке:
Обратите внимание, что в имени ветки не запрещено использовать символ ‘/’, однако, надо быть осторожным, т.к. в файловой системе создаётся папка с именем до ‘/’. Если ветка с таким названием как и папка существует — будет конфликт на уровне файловой системы. Если уже есть ветка dev, то нельзя создать dev/test.
A если есть dev/test, то можно создавать dev/whatever, но нельзя просто dev.
Теперь, в каждой ветке напишем код, который, соответственно, будет запускать и уничтожать наш коллайдер. Последовательность действий приблизительно такая:
Разработка закончена и теперь надо отдать все изменения в master (там ведь старый коллайдер, который ничего не может). Объединение двух коммитов, как и говорилось выше — это merge. Но давайте подумаем, чем отличается ветка master от collider/start и как получить их объединение (сумму)? Например, можно взять общие коммиты этих веток, затем прибавить коммиты, относящиеся только к master, а затем прибавить коммиты, относящиеся только к collider/start. А что у нас? Общие коммиты — есть, только коммиты master — нет, только collider/start — есть. Т.е. объединение этих веток — это master + коммиты от collider/start. Но collider/start — это master + коммиты ветки collider/start! Тоже самое! Т.е. делать ничего не надо! Объединение веток — это и есть collider/start!
Ещё раз, только на буквах, надеюсь, что будет проще для восприятия:
master = C1 + C2 +C3
collider/start = master + C4 = C1 + C2 +C3 + C4
master + collider/start = Общие_коммиты(master, collider/start) + Только_у(master) + Только_у(collider/start) = (C1 + C2 +C3) + (NULL) + (C4) = C1 + C2 +C3 + C4
Как быстро узнать, что fast-forward возможен? Для этого достаточно посмотреть в gitk на две ветки, которые нужно объединить и ответить на один вопрос: существует ли прямой путь от ветки А к B, если двигаться только вверх (от нижней к верхней). Если да — то будет fast-forward.
В теории понятно, пробуем на практике, забираем изменения в master:
Результат (указатель просто передвинулся вперёд):
Объединение
Теперь забираем изменения из collider/terminate. Но, тот, кто дочитал до сюда (дочитал ведь, да?!) заметит, что прямого пути нет и так красиво мы уже не отделаемся. Попробуем git попросить fast-forward:
Что и следовало ожидать. Делаем просто merge:
Я даже рад, что у нас возник конфликт. Обычно, в этом момент некоторые теряются, лезут гуглить и спрашивают, что делать.
Для начала:
Конфликт возникает при попытке объединить два и более коммита, в которых в одной и той же строчке были сделаны изменения. И теперь git не знает что делать: то ли взять первый вариант, то ли второй, то ли старый оставить, то ли всё убрать.
Как всегда, две самые нужные команды нам спешат помочь:
Мы находимся в master, туда же указывает HEAD, туда же и добавляются наши коммиты.
Файл выглядит так:
Из-за того что изменения были в одних и тех же местах конфликтов получилось много. Поэтому, я брал везде первый вариант, а второй копировал сразу после первого, но с gui это сделать довольно просто. Вот результат — вверху варианты файла, внизу — объединение (простите за качество):
Сохраняем результат, закрываем окно, коммитим, смотрим результат:
Мы создали новый коммит, который является объединением двух других. Fast-forward не произошёл, потому, что не было прямого пути для этого, история стала выглядеть чуть-чуть запутаннее. Иногда, merge действительно нужен, но излишне запутанная история тоже ни к чему.
Вот пример реального проекта:
| | |
Конечно, такое никуда не годится! «Но разработка идёт параллельно и никакого fast-forward не будет» скажете вы? Выход есть!
Перестройка
Что же делать, чтобы история оставалась красивой и прямой? Можно взять нашу ветку и перестроить её на другую ветку! Т.е. указать ветке новое начало и воспроизвести все коммиты один за одним. Этот процесс и называется rebase. Наши коммиты станут продолжением той ветки, на которую мы их перестроим. Тогда история будет простой и линейной. И можно будет сделать fast-forward.
Другими словами: мы повторяем историю изменений с одной ветки на другой, как будто бы мы действительно брали другую ветку и заново проделывали эти же самые изменения.
Для начала отменим последние изменения. Проще всего вернуть указатель master назад, на предыдущее состояние. Создавая merge-commit, мы передвинули именно master, поэтому именно его нужно вернуть назад, желательно (а в отдельных случаях важно) на тот же самый commit, где он был.
Как результат, наш merge-commit останется без какого-либо указателя и не будет принадлежать ни к одной ветке.
Используя gitk или консоль перемещаем наш указатель. Поскольку, ветка collider/start уже указывает на наш коммит, нам не нужно искать его id, а мы можем использовать имя ветки (это будет одно и тоже):
Когда с коммита или с нескольких коммитов пропадает указатель (ветка), то коммит остаётся сам по себе. Git про него забывает, не показывает его в логах, в ветках и т.д. Но физически, коммит никуда не пропал. Он живёт себе в репозитории как невостребованная ячейка памяти без указателя и ждёт своего часа, когда git garbage collector её почистит.
Иногда бывает нужно вернуть коммит, который по ошибке был удалён. На помощь придёт git reflog. Он покажет всю историю, по каким коммитам вы ходили (как передвигался указатель HEAD). Используя вывод, можно найти id пропавшего коммита, сделать его checkout или создать на коммит указатель (ветку или тэг).
Выглядит это примерно так (история короткая, поместилась вся):
Посмотрим, что получилось:
Для того, чтобы перестроить одну ветку на другую, нужно найти их общее начало, потом взять коммиты перестраиваемой ветки и, в таком же порядке, применить их на основную (base) ветку. Очень наглядная картинка (feature перестраивается на master):
Важное замечание: после «перестройки» это уже будут новые коммиты. А старые никуда не пропали и не сдвинулись.
В теории разобрались, пробуем на практике. Переключаемся в collider/terminate и перестраиваем на тот коммит, куда указывает master (или collider/start, кому как удобнее). Команда дословно «взять текущую ветку и перестроить её на указанный коммит или ветку»:
Откроется редактор в котором будет приблизительно следующее:
Если коротко: то в процессе перестройки мы можем изменять комментарии к коммитам, редактировать сами коммиты, объединять их или вовсе пропускать. Т.е. можно переписать историю ветки до неузнаваемости. На данном этапе нам это не нужно, просто закрываем редактор и продолжаем. Как и в прошлый раз, конфликтов нам не избежать:
На данном этапе мы удаляли, редактировали, объединяли правки, а на выходе получили красивую линейную историю изменений:
Перерыв
Дальше примеры пойдут по сложнее. Я буду использовать простой скрипт, который будет в файл дописывать случайные строки.
На данном этапе нам не важно, какое содержимое, но было бы очень неплохо иметь много различных коммитов, а не один. Для наглядности.
Скрипт добавляет случайную строчку к файлу и делает git commit. Это повторяется несколько раз:
Передача и приём изменений
git remote
Как отмечалось выше, origin — это имя репозитория по умолчанию. Имена нужны, т.к. репозиториев может быть несколько и их нужно как-то различать. Например, у меня была копия репозитория на флешке и я добавил репозиторий flash. Таким образом я мог работать с двумя репозиториями одновременно: origin и flash.
Имя репозитория используется как префикс к имени ветки, чтоб можно было отличать свою ветку от чужой, например master и origin/master
В справке по git remote достаточно хорошо всё описано. Как и ожидается, там есть команды: add, rm, rename, show.
show покажет основные настройки репозитория:
Чтобы добавить существующий репозиторий используем add :
git fetch
Команда говорит сама за себя: получить изменения.
Стоит отметить, что локально никаких изменений не будет. Git не тронет рабочую копию, не тронет ветки и т.д.
Будут скачены новые коммиты, обновлены только удалённые (remote) ветки и тэги. Это полезно потому, что перед обновлением своего репозитория можно посмотреть все изменения, которые «пришли» к вам.
Ниже есть описание команды push, но сейчас нам нужно передать изменения в origin, чтобы наглядно показать как работает fetch:
Теперь от имени dev2 посмотрим, что есть и получим все изменения:
Выглядит это так:
Обратите внимание, что мы находимся в master.
Что можно сделать:
git checkout origin/master — переключиться на удалённый master, чтобы «пощупать» его. При этом нельзя эту ветку редактировать, но можно создать свою локальную и работать с ней.
git merge origin/master — объединить новые изменения со своими. Т.к. у нас локальных изменений не было, то merge превратится в fast-forward:
git pull
В 95% случаев, вам не нужно менять это поведение.
git push
На все вопросы может ответить расширенный вариант использования команды:
git push origin :
Примеры:
Включаемся в проект
К этому моменту уже более-менее понятно, как работает push, pull. Более смутно представляется в чём разница между merge и rebase. Совсем непонятно зачем это нужно и как применять.
Когда кого-нибудь спрашивают:
— Зачем нужна система контроля версий?
Чаще всего в ответе можно услышать:
— Эта система помогает хранить все изменения в проекте, чтобы ничего не потерялось и всегда можно было «откатиться назад».
А теперь задайте себе вопрос: «как часто приходится откатываться назад?» Часто ли вам нужно хранить больше, чем последнее состояние проекта? Честный ответ будет: «очень редко». Я этот вопрос поднимаю, чтобы выделить гораздо более важную роль системы контроля версий в проекте:
Система контроля версий позволяет вести совместную работу над проектом более, чем одному разработчику.
То, на сколько вам удобно работать с проектом совместно с другими разработчиками и то, на сколько система контроля версий вам помогает в этом — самое важное.
Используете %VCS_NAME%? Удобно? Не ограничивает процесс разработки и легко адаптируется под требования? Быстро? Значит эта %VCS_NAME% подходит для вашего проекта лучше всего. Пожалуй, вам не нужно ничего менять.
Типичные сценарии при работе над проектом
Чтобы добиться такого процесса, нужно чётко определиться где и что будет хранится. Т.к. ветки легковесные (т.е. не тратят ресурсов, места и т.д.) под все задачи можно создать отдельные ветки. Это является хорошей практикой. Такой подход даёт возможность легко оперировать наборами изменений, включать их в различные ветки или полностью исключать неудачные варианты.
Исправление багов
Создадим ветку dev и рассмотрим типичный сценарий исправления багов.
И второй разработчик «забирает» новую ветку к себе:
Пусть 2 разработчика ведут работу каждый над своим багом и делают несколько коммитов (пусть вас не смущает, что я таким некрасивым способом генерирую множество случайных коммитов):
Когда работа закончена, передаём изменения в репозиторий. Dev1:
На первый взгляд, кажется, что здесь много действий и всё как-то сложно. Но, если разобраться, то описание того, что нужно сделать намного больше, чем самой работы. И самое главное, мы уже так делали выше. Приступим к практике:
Посмотрим на результат:
Теперь, всё как положено: наши изменения в dev и готовы быть переданы в origin.
Передаём:
Нам откроется редактор и даст возможность исправить нашу историю, например, поменять порядок коммитов или объединить несколько. Об этом писалось выше. Я оставлю как есть:
После того как все конфликты решены, история будет линейной и логичной. Для наглядности я поменял комментарии (интерактивный rebase даёт эту возможность):
Теперь наша ветка продолжает origin/dev и мы можешь отдать наши изменения: актуальные, адаптированные под новые коммиты:
Далее история повторяется. Для удобства или в случае работы над несколькими багами, как говорилось выше, удобно перед началом работы создать отдельные ветки из dev или origin/dev.
Feature branch
Бывает так, что нужно сделать какой-то большой кусок работы, который не должен попадать в основную версию пока не будет закончен. Над такими ветками могут работать несколько разработчиков. Очень серьёзный и объёмный баг может рассматриваться с точки зрения процесса работы в git как фича — отдельная ветка, над которой работают несколько человек. Сам же процесс точно такой же как и при обычном исправлении багов. Только работа идёт не с dev, а с feature/name веткой.
Вообще, такие ветки могут быть коротко-живущими (1-2 неделя) и долго-живущими (месяц и более). Разумеется, чем дольше живёт ветка, тем чаще её нужно обновлять, «подтягивая» в неё изменения из основной ветки. Чем больше ветка, тем, вероятно, больше будет накладных расходов по её сопровождению.
Начнём с коротко-живущих (short-live feature branches)
Обычно ветка создаётся с самого последнего кода, в нашем случае с ветки dev:
Теперь работу на feature1 можно вести в ветке feature/feature1. Спустя некоторое время в нашей ветке будет много коммитов, и работа над feature1 будет закончена. При этом в dev тоже будет много изменений. И наша задача отдать наши изменения в dev.
Выглядеть это будет приблизительно так:
Ситуация напоминает предыдущую: две ветки, одну нужно объединить с другой и передать в репозиторий. Единственное отличие, это две публичные (удалённые) ветки, а не локальные. Это требует небольшой коммуникации. Когда работа закончена, один разработчик должен предупредить другого, что он собирается «слить» изменения в dev и, например, удалить ветку. Таким образом передавать в эту ветку что-либо будет бессмысленно.
А дальше алгоритм почти такой как и был:
Картинка, feature1 стала частью dev, то что на и нужно было:
Делаем push и чистим за собой ненужное:
Долго-живущие ветки (long-live feature branches)
Сложность долго-живущих веток в их поддержке и актуализации. Если делать всё как описано выше то, вероятно быть беде: время идёт, основная ветка меняется, проект меняется, а ваша фича основана на очень старом варианте. Когда настанет время выпустить фичу, она будет настолько выбиваться из проекта, что объединение может быть очень тяжёлым или, даже, невозможным. Именно поэтому, ветку нужно обновлять. Раз dev уходит вперёд, то мы будем просто время от времени перестраивать нашу ветку на dev.
Всё бы хорошо, но только нельзя просто так взять и перестроить публичную ветку: ветка после ребэйза — это уже новый набор коммитов, совершенно другая история. Она не продолжает то, что уже было. Git не примет такие изменения: два разных пути, нет fast-forward’а. Чтобы переписать историю разработчикам нужно договориться.
Кто-то будет переписывать историю и принудительно выкладывать новый вариант, а в этот момент остальные не должны передавать свои изменения в текущую ветку, т.к. она будет перезаписана и всё пропадёт. Когда первый разработчик закончит, все остальные перенесут свои коммиты, которые они успеют сделать во время переписи уже на новую ветку. Кто говорил, что нельзя ребэйзить публичные ветки?
Приступим к практике:
Второй разработчик подключается к работе всё стандартно:
Добавим ещё несколько коммитов в основную ветку dev и история будет такая:
Настало время актуализировать feature/long, но при этом разработка должна продолжиться отдельно. Пусть перестраивать будет dev1. Тогда он предупреждает dev2 об этом и начинает:
В это время dev2 продолжает работать, но знает, что ему нельзя делать push, т.к. нужной ветки ещё нет (а текущая будет удалена).
Первый заканчивает rebase и история будет такой:
Ветка перестроена, а origin/feature/long остался там, где и был. Цели мы достигли, теперь нужно поделиться со всеми:
Git лишний раз напоминает, что что-то не так. Но теперь, мы точно знаем, что мы делаем, и знаем, что так надо:
Теперь можно работать дальше предупредив остальных об окончании работ.
Посмотрим, как эти изменения отразились на окружающих и на dev2 в частности:
N, чтобы указать на предыдущий N-ый коммит.
HEAD
1 — это предыдущий, а HEAD
2 — это предпредыдущий. HEAD
5 — 5 коммитов назад. Удобно, чтобы не запоминать id.
Посмотрим, как теперь нам перестроить только один коммит:
1
Если бы нам надо было перетянуть 4 коммита, то было бы feature/long
Осталось продолжить работу.
Hotfixes
Hotfixы нужны, т.к. бывают очень критичные баги, которые нужно исправить как можно быстрее. При этом нельзя передать вместе с hotfix-ом последний код, т.к. он не оттестирован и на полное тестирование нет времени. Нужно только это исправление, максимально быстро и оттестированное. Чтобы это сделать, достаточно взять последний релиз, который был отправлен на продакшен. Это тот, где у вас остался tag или master. Тэги играют очень важную роль, помогая понять что именно было собрано и куда это попало.
Тэги делаются командой
Всякие полезности
Git позволяет настраивать aliasы для различных команд. Это бывает очень удобно и сокращает время набора команд. Приводить здесь примеры не буду, в Интернете их полно, просто поищите.
Перед тем, как отдавать свои изменения их можно перестроить на самих себя, чтобы привести историю в порядок.
Например, в логах может быть такое:
Перестроим сами себя, но начиная с 6 коммитов назад:
Теперь в интерактивном режиме можно объединить (squash) первые два коммита в один и последние четыре. Тогда история будет выглядеть так:
Такое намного приятнее передавать в общим репозиторий.
Выводы
Причемания и апдейты
gcc рекомендовал посмотреть на Git Extensions.
borNfree подсказал ещё один GUI клиент Source Tree.
zloylos поделился ссылкой на визуализатор для git
olancheg предложил посмотреть на ещё один туториал для новичков.
PS. Что тут обычно пишут, когда первый пост на хабре? Прошу не судить строго, писал как мог.


