Автор: Wagner Crivelini
Опубликовано: 09.07.2010
Версия текста: 1.1
Первое, что мы узнаем об SQL – это как писать выражения SELECT для выборки данных из таблицы. Такие выражения выглядят просто и очень похоже на обычный разговорный язык.
Но настоящие запросы зачастую гораздо сложнее, чем простые выражения SELECT.
Во-первых, нужные данные обычно разбиты на несколько разных таблиц. Это естественное следствие нормализации данных, которая является характерным свойством любой хорошо спланированной модели БД. SQL позволяет объединить эти данные.
В прошлом администраторы БД и разработчики помещали все нужные таблицы и/или представления в оператор FROM, а затем использовали оператор WHERE, чтобы определить, как должны комбинироваться записи из одной таблицы с записями из другой (чтобы сделать этот текст чуть-чуть более читаемым, я в дальнейшем буду писать просто «таблица», а не «таблица и/или представление»).
Однако, чтобы стандартизовать объединение данных, понадобилось довольно много времени. Это было сделано с помощью оператора JOIN (ANSI-SQL 92). К сожалению, некоторые детали использования оператора JOIN так и остаются неизвестными очень многим.
Прежде чем показать различный синтаксис JOIN, поддерживаемый T-SQL (в SQL Server 2008), я опишу несколько концепций, которые не следует забывать при любом соединении данных из двух или нескольких таблиц.
Начало: одна таблица, никакого JOIN
Если запрос обращается только к одному объекту, синтаксис будет очень простым, и никакое соединение не потребуется. Выражение будет старым добрым » SELECT fields FROM object » с другими необязательными операторами (то есть WHERE, GROUP BY, HAVING или ORDER BY).
Однако конечные пользователи не знают, что администраторы БД обычно прячут множество сложных соединений за одним красивым и простым в использовании представлением. Это делается по разным причинам, от безопасности данных до производительности БД. Например, администратор может дать конечному пользователю разрешение на доступ к одному представлению вместо нескольких рабочих таблиц, что, очевидно, повышает сохранность данных. А если говорить о производительности, можно создать представление, используя правильные параметры для соединения записей из разных таблиц, правильно использовать индексы и тем самым повысит производительность запроса.
Как бы то ни было, соединения в БД всегда есть, даже если конечный пользователь их и не видит.
Логика, стоящая за соединением таблиц
Много лет назад, когда я начинал работать с SQL, я узнал, что есть несколько типов соединения данных. Но мне потребовалось некоторое время, чтобы точно понять, что я делаю, соединяя таблицы. Возможно из-за того, что люди боятся математики, не часто можно услышать, что вся идея соединений таблиц – это теория множеств. Несмотря на заковыристое название, концепция так проста, что изучается в начальной школе.
Рисунок 1 очень похож на картинки из учебника для первого класса. Идея в том, чтобы найти в разных множествах соответствующие объекты. Это как раз то, чем занимается JOIN в SQL!
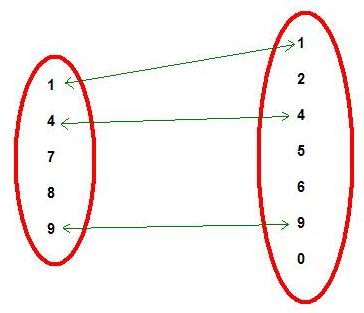
Рисунок 1. Комбинируем объекты из разных множеств.
Если вы поняли эту аналогию, все становится более осмысленным.
Представьте, что 2 множества на рисунке 1 – это таблицы, а цифры – это ключи, используемые для соединения таблиц. Таким образом, в каждом из множеств вместо целой записи мы видим только ключевые поля каждой таблицы. Результирующий набор комбинаций будет определяться типом используемого соединения, и это я как раз и собираюсь показать. Чтобы проиллюстрировать примеры, возьмем 2 таблицы, показанные ниже:
Скрипт для создания и заполнения таблиц приведен ниже:
Как можно заметить, этот скрипт не полностью обеспечивает ссылочную целостность. Я намеренно оставил таблицы без внешних ключей, чтобы лучше объяснить функциональность разных типов JOIN. Но я сделал это исключительно в целях обучения. Внешние ключи крайне полезны для обеспечения непротиворечивости данных, и их нельзя исключить ни из одной реальной БД.
Теперь мы готовы. Давайте рассмотрим типы JOIN, имеющиеся в T-SQL, их синтаксис и результаты, генерируемые ими.
INNER JOIN
Это наиболее часто используемое в SQL соединение. Оно возвращает пересечение двух множеств. В терминах таблиц, оно возвращает только записи из обеих таблиц, отвечающие указанному критерию.
На рисунке 2 показана диаграмма Венна, иллюстрирующая пересечение двух таблиц. Результат операции – закрашенная область.
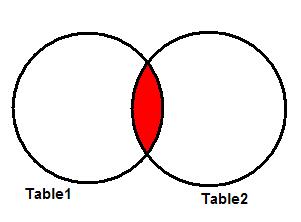
Рисунок 2. INNER JOIN.
Теперь посмотрите на синтаксис объединения данных из таблиц Table1 и Table2 с использованием INNER JOIN.
Вот набор результатов, возвращаемый этим выражением:
Противоположностью INNER JOIN является OUTER JOIN. Существует три типа OUTER JOIN – полный, левый и правый. Рассмотрим каждый из них.
FULL JOIN
Полностью это соединение называется FULL OUTER JOIN (зарезервированное слово OUTER необязательно). FULL JOIN работает как объединение двух множеств. На рисунке 3 показана диаграмма Венна для FULL JOIN двух таблиц. Результатом операции опять же является закрашенная область.
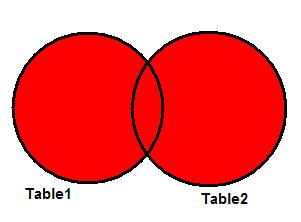
Рисунок 3. FULL JOIN.
Синтаксис почти такой же, как показанный выше:
Набор результатов, возвращаемых этим выражением, выглядит так:
LEFT JOIN
Также известен как LEFT OUTER JOIN, и является частным случаем FULL JOIN. Дает все запрошенные данные из таблицы в левой части JOIN плюс данные из правой таблицы, пересекающиеся с первой таблицей. На рисунке 4 показана диаграмма Венна, иллюстрирующая LEFT JOIN для двух таблиц.
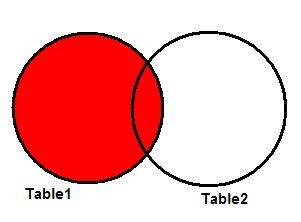
Рисунок 4. LEFT JOIN.
Результатом этого выражения будет:
RIGHT JOIN
Также известен как RIGHT OUTER JOIN, и является еще одним частным случаем FULL JOIN. Он выдает все запрошенные данные из таблицы, стоящей в правой части оператора JOIN, плюс данные из левой таблицы, пересекающиеся с правой. Диаграмма Венна для RIGHT JOIN двух таблиц показана на рисунке 5.
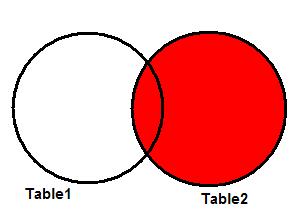
Рисунок 5. RIGHT JOIN.
Как видите, синтаксис очень похож на показанный выше:
Результатом этого выражения будет:
CROSS JOIN
Я не верю, что есть какой-то способ представить этот результат в виде диаграммы Венна. Я предполагаю, что это должно быть трехмерное изображение. Если это действительно так, то диаграмма будет более запутывающей, чем объяснение.
Синтаксис CROSS JOIN таков:
Поскольку в Table1 содержится 5 записей, а в Table2 – еще 7, результат этого запроса будет содержать 35 записей (5 x 7).
Совершенно честно, я не могу сейчас припомнить ни одной реальной ситуации, когда мне понадобилось бы сгенерировать декартово произведение двух таблиц. Но если оно вам понадобится, есть CROSS JOIN.
Кроме всего прочего, стоит подумать и о производительности. Допустим, что вы случайно запустили на рабочем сервере запрос, содержащий CROSS JOIN для двух таблиц по миллиону записей в каждой. Это, несомненно, добавит вам головной боли. Возможно, у вашего сервера начнутся проблемы с производительностью, поскольку это запрос будет исполняться долго, и потреблять при этом существенное количество ресурсов сервера.
SELF JOIN
Оператор JOIN можно использовать для комбинирования любой пары таблиц, включая комбинацию таблицы с самой собой. Это и есть «SELF JOIN».
Посмотрите на классический пример, возвращающий имя начальника сотрудника (по таблице 1). В этом примере мы полагаем, что значение в field2 – фактически кодовый номер босса, следовательно, он связан с key1.
А вот результат запроса:
Последняя запись в данном примере показывает, что у Гарри нет начальника, другими словами, он №1 в иерархии компании.
Исключение пересечения множеств
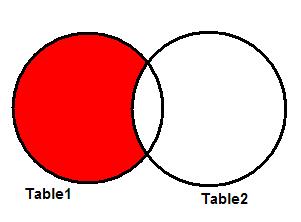
Рисунок 6. Непересекающиеся записи в Таблице 1.
Можно в этом запросе написать LEFT JOIN, например:
И, наконец, набор результатов будет выглядеть так:
При выполнении таких запросов нужно правильно выбирать поле для оператора WHERE. Нужно использовать поле, не допускающее NULL-значений. В противном случае набор результатов может содержать ненужные записи. Поэтому я и предложил использовать ключ второй таблицы, точнее, ее первичный ключ. Поскольку первичные ключи не могут содержать NULL-значения, это гарантирует, что набор результатов будет таким, как и предполагалось.
Слово о планах исполнения
По ходу действия мы подошли к важному моменту. Обычно мы не задумываемся об этом, но нужно знать, что планы исполнения SQL-запросов сперва вычисляют результат операторов FROM и JOIN (если таковой имеется), а только затем исполняют оператор WHERE.
Это верно как для SQL Server, так и для любой другой РСУБД.
Базовое понимание работы SQL важно для любого администратора БД или разработчика. Это помогает в работе. Если вам интересно, посмотрите на план выполнения запроса, приведенного выше (рисунок 7).
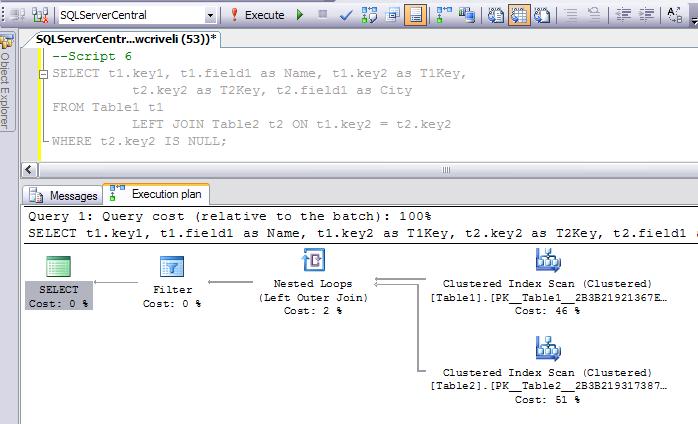
Рисунок 7. План исполнения запроса, использующего LEFT JOIN.
JOIN и индексы
Посмотрите еще раз на план исполнения запроса. Заметьте, он использует кластерные индексы для обеих таблиц. Использование индексов – лучший способ ускорить выполнение запросов. Но нужно обращать внимание на ряд деталей.
При создании запросов мы ожидаем, что SQL Server Query Optimizer будет использовать индексы таблиц для увеличения производительности. Мы также можем помочь Query Optimizer-у выбрать индексированные поля, являющиеся частью запроса.
Лично я считаю, что внешние ключи должны присутствовать во всех реальных моделях БД. Причем это хорошая идея – создавать некластерные индексы для всех внешних ключей. Вы всегда будете исполнять множество запросов, а также использовать оператор JOIN, основываясь на первичных и внешних ключах.
Важно: SQL Server автоматически создает кластерный индекс для первичных ключей. Однако по умолчанию он ничего не делает с внешними ключами. Проверьте, что ваша СУБД настроена надлежащим образом.
Неравенства
Осмысляем работу джойнов в SQL: от реляционной алгебры до наглядных картинок
Выбираем, какие фильмы посмотреть, с помощью соединения данных в SQL.

Опять эта проблема — выбрать кино на вечер. Благодаря стриминговым сервисам доступны едва ли не все фильмы мира: это бесконечное полотно с постерами и фильтры, фильтры, фильтры…

МОЗГ: Поставлю-ка я фильтр по стране: пусть будет Дания, и добавлю ограничение по жанру — триллер… Ну вот — другое дело, относительно небольшой список.
— Мозг, а знаешь почему? Да потому что здесь только фильмы, которые сняты в Дании И помечены как триллеры.
— Да не знаю я, как задать такие критерии в этом сервисе. Вот если бы можно было писать на SQL — тут бы решение нашлось для любой комбинации признаков.
— Легко! Ещё и картинки будут. У меня и база фильмов уже спарсена — тренируйся не хочу.

Фулстек-разработчик. Любимый стек: Java + Angular, но в хорошей компании готова писать хоть на языке Ада.
Договоримся об обозначениях
Назовём множество датских фильмов — D, а множество триллеров — T. У каждого фильма будет уникальный номер, он же ключ. Раз ключ — пусть зовётся Key.
Заодно вспомним, как на SQL пишется простой запрос для связывания данных из двух таблиц:
INNER JOIN
Если не уточнить тип соединения ( JOIN), то по умолчанию применяется INNER JOIN — как раз тот вариант, который сработал в нашем кинофильтре. Это он выбирает и триллеры, и датские фильмы одновременно.
Понимание джойнов сломано. Это точно не пересечение кругов, честно
Так получилось, что я провожу довольно много собеседований на должность веб-программиста. Один из обязательных вопросов, который я задаю — это чем отличается INNER JOIN от LEFT JOIN.
Чаще всего ответ примерно такой: «inner join — это как бы пересечение множеств, т.е. остается только то, что есть в обеих таблицах, а left join — это когда левая таблица остается без изменений, а от правой добавляется пересечение множеств. Для всех остальных строк добавляется null». Еще, бывает, рисуют пересекающиеся круги.
Я так устал от этих ответов с пересечениями множеств и кругов, что даже перестал поправлять людей.
Дело в том, что этот ответ в общем случае неверен. Ну или, как минимум, не точен.
Давайте рассмотрим почему, и заодно затронем еще парочку тонкостей join-ов.
Во-первых, таблица — это вообще не множество. По математическому определению, во множестве все элементы уникальны, не повторяются, а в таблицах в общем случае это вообще-то не так. Вторая беда, что термин «пересечение» только путает.
(Update. В комментах идут жаркие споры о теории множеств и уникальности. Очень интересно, много нового узнал, спасибо)
INNER JOIN
Давайте сразу пример.
Итак, создадим две одинаковых таблицы с одной колонкой id, в каждой из этих таблиц пусть будет по две строки со значением 1 и еще что-нибудь.
Давайте, их, что ли, поджойним
Если бы это было «пересечение множеств», или хотя бы «пересечение таблиц», то мы бы увидели две строки с единицами.

На практике ответ будет такой:
Для начала рассмотрим, что такое CROSS JOIN. Вдруг кто-то не в курсе.
CROSS JOIN — это просто все возможные комбинации соединения строк двух таблиц. Например, есть две таблицы, в одной из них 3 строки, в другой — 2:
Тогда CROSS JOIN будет порождать 6 строк.
Так вот, вернемся к нашим баранам.
Конструкция
— это, можно сказать, всего лишь синтаксический сахар к
Небольшой disclaimer: хотя inner join логически эквивалентен cross join с фильтром, это не значит, что база будет делать именно так, в тупую: генерить все комбинации и фильтровать. На самом деле там более интересные алгоритмы.
LEFT JOIN
Если вы считаете, что левая таблица всегда остается неизменной, а к ней присоединяется или значение из правой таблицы или null, то это в общем случае не так, а именно в случае когда есть повторы данных.
Опять же, создадим две таблицы:
Теперь сделаем LEFT JOIN:
Результат будет содержать 5 строк, а не по количеству строк в левой таблице, как думают очень многие.
Так что, LEFT JOIN — это тоже самое что и INNER JOIN (т.е. все комбинации соединений строк, отфильтрованных по какому-то условию), и плюс еще записи из левой таблицы, для которых в правой по этому фильтру ничего не совпало.
LEFT JOIN можно переформулировать так:
Сложноватое объяснение, но что поделать, зато оно правдивее, чем круги с пересечениями и т.д.
Условие ON
Удивительно, но по моим ощущениям 99% разработчиков считают, что в условии ON должен быть id из одной таблицы и id из второй. На самом деле там любое булево выражение.
Например, есть таблица со статистикой юзеров users_stats, и таблица с ip адресами городов.
Тогда к статистике можно прибавить город
где && — оператор пересечения (см. расширение посгреса ip4r)
Если в условии ON поставить true, то это будет полный аналог CROSS JOIN
Производительность
Есть люди, которые боятся join-ов как огня. Потому что «они тормозят». Знаю таких, где есть полный запрет join-ов по проекту. Т.е. люди скачивают две-три таблицы себе в код и джойнят вручную в каком-нибудь php.
Это, прямо скажем, странно.
Если джойнов немного, и правильно сделаны индексы, то всё будет работать быстро. Проблемы будут возникать скорее всего лишь тогда, когда у вас таблиц будет с десяток в одном запросе. Дело в том, что планировщику нужно определить, в какой последовательности осуществлять джойны, как выгоднее это сделать.
Сложность этой задачи O(n!), где n — количество объединяемых таблиц. Поэтому для большого количества таблиц, потратив некоторое время на поиски оптимальной последовательности, планировщик прекращает эти поиски и делает такой план, какой успел придумать. В этом случае иногда бывает выгодно вынести часть запроса в подзапрос CTE; например, если вы точно знаете, что, поджойнив две таблицы, мы получим очень мало записей, и остальные джойны будут стоить копейки.
Кстати, Еще маленький совет по производительности. Если нужно просто найти элементы в таблице, которых нет в другой таблице, то лучше использовать не ‘LEFT JOIN… WHERE… IS NULL’, а конструкцию EXISTS. Это и читабельнее, и быстрее.
Выводы
Как мне кажется, не стоит использовать диаграммы Венна для объяснения джойнов. Также, похоже, нужно избегать термина «пересечение».
Как объяснить на картинке джойны корректно, я, честно говоря, не представляю. Если вы знаете — расскажите, плиз, и киньте в коменты. А мы обсудим это в одном из ближайших выпусков подкаста «Цинковый прод». Не забудьте подписаться.
Учебник по языку SQL (DDL, DML) на примере диалекта MS SQL Server. Часть четвертая
Предыдущие части
В данной части мы рассмотрим
Добавим немного новых данных
Для демонстрационных целей добавим несколько отделов и должностей:
JOIN-соединения – операции горизонтального соединения данных
Здесь нам очень пригодится знание структуры БД, т.е. какие в ней есть таблицы, какие данные хранятся в этих таблицах и по каким полям таблицы связаны между собой. Первым делом всегда досконально изучайте структуру БД, т.к. нормальный запрос можно написать только тогда, когда ты знаешь, что откуда берется. У нас структура состоит из 3-х таблиц Employees, Departments и Positions. Приведу здесь диаграмму из первой части:
Если суть РДБ – разделяй и властвуй, то суть операций объединений снова склеить разбитые по таблицам данные, т.е. привести их обратно в человеческий вид.
Если говорить просто, то операции горизонтального соединения таблицы с другими таблицами используются для того, чтобы получить из них недостающие данные. Вспомните пример с еженедельным отчетом для директора, когда при запросе из таблицы Employees, нам для получения окончательного результата недоставало поля «Название отдела», которое находится в таблице Departments.
Понимание каждого вида соединения очень важно, т.к. от применения того или иного вида, результат запроса может отличаться. Сравните результаты одного и того же запроса с применением разного типа соединения, попробуйте пока просто увидеть разницу и идите дальше (мы сюда еще вернемся):
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | NULL | NULL |
| NULL | NULL | NULL | 4 | Маркетинг и реклама |
| NULL | NULL | NULL | 5 | Логистика |
| ID | Name | DepartmentID | ID | Name |
|---|---|---|---|---|
| 1000 | Иванов И.И. | 1 | 1 | Администрация |
| 1001 | Петров П.П. | 3 | 1 | Администрация |
| 1002 | Сидоров С.С. | 2 | 1 | Администрация |
| 1003 | Андреев А.А. | 3 | 1 | Администрация |
| 1004 | Николаев Н.Н. | 3 | 1 | Администрация |
| 1005 | Александров А.А. | NULL | 1 | Администрация |
| 1000 | Иванов И.И. | 1 | 2 | Бухгалтерия |
| 1001 | Петров П.П. | 3 | 2 | Бухгалтерия |
| 1002 | Сидоров С.С. | 2 | 2 | Бухгалтерия |
| 1003 | Андреев А.А. | 3 | 2 | Бухгалтерия |
| 1004 | Николаев Н.Н. | 3 | 2 | Бухгалтерия |
| 1005 | Александров А.А. | NULL | 2 | Бухгалтерия |
| 1000 | Иванов И.И. | 1 | 3 | ИТ |
| 1001 | Петров П.П. | 3 | 3 | ИТ |
| 1002 | Сидоров С.С. | 2 | 3 | ИТ |
| 1003 | Андреев А.А. | 3 | 3 | ИТ |
| 1004 | Николаев Н.Н. | 3 | 3 | ИТ |
| 1005 | Александров А.А. | NULL | 3 | ИТ |
| 1000 | Иванов И.И. | 1 | 4 | Маркетинг и реклама |
| 1001 | Петров П.П. | 3 | 4 | Маркетинг и реклама |
| 1002 | Сидоров С.С. | 2 | 4 | Маркетинг и реклама |
| 1003 | Андреев А.А. | 3 | 4 | Маркетинг и реклама |
| 1004 | Николаев Н.Н. | 3 | 4 | Маркетинг и реклама |
| 1005 | Александров А.А. | NULL | 4 | Маркетинг и реклама |
| 1000 | Иванов И.И. | 1 | 5 | Логистика |
| 1001 | Петров П.П. | 3 | 5 | Логистика |
| 1002 | Сидоров С.С. | 2 | 5 | Логистика |
| 1003 | Андреев А.А. | 3 | 5 | Логистика |
| 1004 | Николаев Н.Н. | 3 | 5 | Логистика |
| 1005 | Александров А.А. | NULL | 5 | Логистика |
Настало время вспомнить про псевдонимы таблиц
Пришло время вспомнить про псевдонимы таблиц, о которых я рассказывал в начале второй части.
В многотабличных запросах, псевдоним помогает нам явно указать из какой именно таблицы берется поле. Посмотрим на пример:
В нем поля с именами ID и Name есть в обоих таблицах и в Employees, и в Departments. И чтобы их различать, мы предваряем имя поля псевдонимом и точкой, т.е. «emp.ID», «emp.Name», «dep.ID», «dep.Name».
Вспоминаем почему удобнее пользоваться именно короткими псевдонимами – потому что, без псевдонимов наш запрос бы выглядел следующим образом:
По мне, стало очень длинно и хуже читаемо, т.к. имена полей визуально потерялись среди повторяющихся имен таблиц.
В многотабличных запросах, хоть и можно указать имя без псевдонима, в случае если имя не дублируется во второй таблице, но я бы рекомендовал всегда использовать псевдонимы в случае соединения, т.к. никто не гарантирует, что поле с таким же именем со временем не добавят во вторую таблицу, а тогда ваш запрос просто сломается, ругаясь на то что он не может понять к какой таблице относится данное поле.
Только используя псевдонимы, мы сможем осуществить соединения таблицы самой с собой. Предположим встала задача, получить для каждого сотрудника, данные сотрудника, который был принят прямо до него (табельный номер отличается на единицу меньше). Допустим, что у нас табельные номера выдаются последовательно и без дырок, тогда мы можем это сделать примерно следующим образом:
Т.е. здесь одной таблице Employees, мы дали псевдоним «e1», а второй «e2».
Разбираем каждый вид горизонтального соединения
Для этой цели рассмотрим 2 небольшие абстрактные таблицы, которые так и назовем LeftTable и RightTable:
Посмотрим, что в этих таблицах:
| LCode | LDescr |
|---|---|
| 1 | L-1 |
| 2 | L-2 |
| 3 | L-3 |
| 5 | L-5 |
| RCode | RDescr |
|---|---|
| 2 | B-2 |
| 3 | B-3 |
| 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
Здесь были возвращены объединения строк для которых выполнилось условие (l.LCode=r.RCode)
LEFT JOIN
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
Здесь были возвращены все строки LeftTable, которые были дополнены данными строк из RightTable, для которых выполнилось условие (l.LCode=r.RCode)
RIGHT JOIN
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
Здесь были возвращены все строки RightTable, которые были дополнены данными строк из LeftTable, для которых выполнилось условие (l.LCode=r.RCode)
По сути если мы переставим LeftTable и RightTable местами, то аналогичный результат мы получим при помощи левого соединения:
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
Я за собой заметил, что я чаще применяю именно LEFT JOIN, т.е. я сначала думаю, данные какой таблицы мне важны, а потом думаю, какая таблица/таблицы будет играть роль дополняющей таблицы.
FULL JOIN – это по сути одновременный LEFT JOIN + RIGHT JOIN
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| NULL | NULL | 4 | B-4 |
Вернулись все строки из LeftTable и RightTable. Строки для которых выполнилось условие (l.LCode=r.RCode) были объединены в одну строку. Отсутствующие в строке данные с левой или правой стороны заполняются NULL-значениями.
CROSS JOIN
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | 2 | B-2 |
| 2 | L-2 | 2 | B-2 |
| 3 | L-3 | 2 | B-2 |
| 5 | L-5 | 2 | B-2 |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2 | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2 | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
Каждая строка LeftTable соединяется с данными всех строк RightTable.
Возвращаемся к таблицам Employees и Departments
Надеюсь вы поняли принцип работы горизонтальных соединений. Если это так, то возвратитесь на начало раздела «JOIN-соединения – операции горизонтального соединения данных» и попробуйте самостоятельно понять примеры с объединением таблиц Employees и Departments, а потом снова возвращайтесь сюда, обсудим это вместе.
Давайте попробуем вместе подвести резюме для каждого запроса:
| Запрос | Резюме |
|---|---|
| По сути данный запрос вернет только сотрудников, у которых указано значение DepartmentID. Т.е. мы можем использовать данное соединение, в случае, когда нам нужны данные по сотрудникам числящихся за каким-нибудь отделом (без учета внештаткиков). | |
| Вернет всех сотрудников. Для тех сотрудников у которых не указан DepartmentID, поля «dep.ID» и «dep.Name» будут содержать NULL. Вспоминайте, что NULL значения в случае необходимости можно обработать, например, при помощи ISNULL(dep.Name,’вне штата’). Этот вид соединения можно использовать, когда нам важно получить данные по всем сотрудникам, например, чтобы получить список для начисления ЗП. | |
| Здесь мы получили дырки слева, т.е. отдел есть, но сотрудников в этом отделе нет. Такое соединение можно использовать, например, когда нужно выяснить, какие отделы и кем у нас заняты, а какие еще не сформированы. Эту информацию можно использовать для поиска и приема новых работников из которых будет формироваться отдел. | |
| Этот запрос важен, когда нам нужно получить все данные по сотрудникам и все данные по имеющимся отделам. Соответственно получаем дырки (NULL-значения) либо по сотрудникам, либо по отделам (внештатники). Данный запрос, например, может использоваться в целях проверки, все ли сотрудники сидят в правильных отделах, т.к. может у некоторых сотрудников, которые числятся как внештатники, просто забыли указать отдел. | |
| В таком виде даже сложно придумать где это можно применить, поэтому пример с CROSS JOIN я покажу ниже. |
Обратите внимание, что в случае повторения значений DepartmentID в таблице Employees, произошло соединение каждой такой строки со строкой из таблицы Departments с таким же ID, то есть данные Departments объединились со всеми записями для которых выполнилось условие (emp.DepartmentID=dep.ID):
В нашем случае все получилось правильно, т.е. мы дополнили таблицу Employees, данными таблицы Departments. Я специально заострил на этом внимание, т.к. бывают случаи, когда такое поведение нам не нужно. Для демонстрации поставим задачу – для каждого отдела вывести последнего принятого сотрудника, если сотрудников нет, то просто вывести название отдела. Возможно напрашивается такое решение – просто взять предыдущий запрос и поменять условие соединение на RIGHT JOIN, плюс переставить поля местами:
| ID | Name | ID | Name |
|---|---|---|---|
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1001 | Петров П.П. |
| 3 | ИТ | 1003 | Андреев А.А. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
| 4 | Маркетинг и реклама | NULL | NULL |
| 5 | Логистика | NULL | NULL |
Но мы для ИТ-отдела получили три строчки, когда нам нужна была только строчка с последним принятым сотрудником, т.е. Николаевым Н.Н.
Задачу такого рода, можно решить, например, при помощи использования подзапроса:
| ID | Name | ID | Name |
|---|---|---|---|
| 1 | Администрация | 1000 | Иванов И.И. |
| 2 | Бухгалтерия | 1002 | Сидоров С.С. |
| 3 | ИТ | 1004 | Николаев Н.Н. |
| 4 | Маркетинг и реклама | NULL | NULL |
| 5 | Логистика | NULL | NULL |
При помощи предварительного объединения Employees с данными подзапроса, мы смогли оставить только нужных нам для соединения с Departments сотрудников.
Здесь мы плавно переходим к использованию подзапросов. Я думаю использование их в таком виде должно быть для вас понятно на интуитивном уровне. То есть подзапрос подставляется на место таблицы и играет ее роль, ничего сложного. К теме подзапросов мы еще вернемся отдельно.
Посмотрите отдельно, что возвращает подзапрос:
| MaxEmployeeID |
|---|
| 1005 |
| 1000 |
| 1002 |
| 1004 |
Т.е. он вернул только идентификаторы последних принятых сотрудников, в разрезе отделов.
Соединения выполняются последовательно сверху-вниз, наращиваясь как снежный ком, который катится с горы. Сначала происходит соединение «Employees emp JOIN (Подзапрос) lastEmp», формируя новый выходной набор:
Потом идет объединение набора, полученного «Employees emp JOIN (Подзапрос) lastEmp» (назовем его условно «ПоследнийРезультат») с Departments, т.е. «ПоследнийРезультат RIGHT JOIN Departments dep»:
Самостоятельная работа для закрепления материала
Если вы новичок, то вам обязательно нужно прорабатывать каждую JOIN-конструкцию, до тех пор, пока вы на 100% не будете понимать, как работает каждый вид соединения и правильно представлять результат какого вида будет получен в итоге.
Для закрепления материала про JOIN-соединения сделаем следующее:
Посмотрим, что в таблицах:
| LCode | LDescr |
|---|---|
| 1 | L-1 |
| 2 | L-2a |
| 2 | L-2b |
| 3 | L-3 |
| 5 | L-5 |
| RCode | RDescr |
|---|---|
| 2 | B-2a |
| 2 | B-2b |
| 3 | B-3 |
| 4 | B-4 |
А теперь попытайтесь сами разобрать, каким образом получилась каждая строчка запроса с каждым видом соединения (Excel вам в помощь):
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| NULL | NULL | 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | NULL | NULL |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2a |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | NULL | NULL |
| NULL | NULL | 4 | B-4 |
| LCode | LDescr | RCode | RDescr |
|---|---|---|---|
| 1 | L-1 | 2 | B-2a |
| 2 | L-2a | 2 | B-2a |
| 2 | L-2b | 2 | B-2a |
| 3 | L-3 | 2 | B-2a |
| 5 | L-5 | 2 | B-2a |
| 1 | L-1 | 2 | B-2b |
| 2 | L-2a | 2 | B-2b |
| 2 | L-2b | 2 | B-2b |
| 3 | L-3 | 2 | B-2b |
| 5 | L-5 | 2 | B-2b |
| 1 | L-1 | 3 | B-3 |
| 2 | L-2a | 3 | B-3 |
| 2 | L-2b | 3 | B-3 |
| 3 | L-3 | 3 | B-3 |
| 5 | L-5 | 3 | B-3 |
| 1 | L-1 | 4 | B-4 |
| 2 | L-2a | 4 | B-4 |
| 2 | L-2b | 4 | B-4 |
| 3 | L-3 | 4 | B-4 |
| 5 | L-5 | 4 | B-4 |
Еще раз про JOIN-соединения
Еще один пример с использованием нескольких последовательных операций соединении. Здесь повтор получился не специально, так получилось – не выбрасывать же материал. 😉 Но ничего «повторение – мать учения».
Если используется несколько операций соединения, то в таком случае они применяются последовательно сверху-вниз. Грубо говоря, после каждого соединения создается новый набор и следующее соединение уже происходит с этим расширенным набором. Рассмотрим простой пример:
Первым делом выбрались все записи таблицы Employees:
Дальше произошло соединение с таблицей Departments:
Дальше уже идет соединение этого набора с таблицей Positions:
Т.е. это выглядит примерно так:
И в последнюю очередь идет возврат тех данных, которые мы просим вывести:
Соответственно, ко всему этому полученному набору можно применить фильтр WHERE и сортировку ORDER BY:
| ID | EmployeeName | PositionName | DepartmentName |
|---|---|---|---|
| 1004 | Николаев Н.Н. | Программист | ИТ |
| 1001 | Петров П.П. | Программист | ИТ |
То есть последний полученный набор – представляет собой такую же таблицу, над которой можно выполнять базовый запрос:
То есть если раньше в роли источника выступала только одна таблица, то теперь на это место мы просто подставляем наше выражение:
В результате чего получаем тот же самый базовый запрос:
А теперь, применим группировку:
Видите, мы все так же крутимся вокруг да около базовых конструкций, теперь надеюсь понятно, почему очень важно в первую очередь хорошо понять их.
И как мы увидели, в запросе на месте любой таблицы может стоять подзапрос. В свою очередь подзапросы могут быть вложены в подзапросы. И все эти подзапросы тоже представляют из себя базовые конструкции. То есть базовая конструкция, это кирпичики, из которых строится любой запрос.
Обещанный пример с CROSS JOIN
Давайте используем соединение CROSS JOIN, чтобы подсчитать сколько сотрудников, в каком отделе и на каких должностях числится. Для каждого отдела перечислим все существующие должности:
В данном случае сначала выполнилось соединение при помощи CROSS JOIN, а затем к полученному набору сделалось соединение с данными из подзапроса при помощи LEFT JOIN. Вместо таблицы в LEFT JOIN мы использовали подзапрос.
Подзапрос заключается в скобки и ему присваивается псевдоним, в данном случае это «e». То есть в данном случае объединение происходит не с таблицей, а с результатом следующего запроса:
| DepartmentID | PositionID | EmplCount |
|---|---|---|
| NULL | NULL | 1 |
| 2 | 1 | 1 |
| 1 | 2 | 1 |
| 3 | 3 | 2 |
| 3 | 4 | 1 |
Вместе с псевдонимом «e» мы можем использовать имена DepartmentID, PositionID и EmplCount. По сути дальше подзапрос ведет себя так же, как если на его месте стояла таблица. Соответственно, как и у таблицы,
все имена колонок, которые возвращает подзапрос, должны быть заданы явно и не должны повторяться.
Связь при помощи WHERE-условия
Для примера перепишем следующий запрос с JOIN-соединением:
Через WHERE-условие он примет следующую форму:
Здесь плохо то, что происходит смешивание условий соединения таблиц (emp.DepartmentID=dep.ID) с условием фильтрации (emp.DepartmentID=3).
Теперь посмотрим, как сделать CROSS JOIN:
Через WHERE-условие он примет следующую форму:
Т.е. в этом случае мы просто не указали условие соединения таблиц Employees и Departments. Чем плох этот запрос? Представьте, что кто-то другой смотрит на ваш запрос и думает «кажется тот, кто писал запрос забыл здесь дописать условие (emp.DepartmentID=dep.ID)» и с радостью, что обнаружил косяк, дописывает это условие. В результате чего задуманное вами может сломаться, т.к. вы подразумевали CROSS JOIN. Так что, если вы делаете декартово соединение, то лучше явно укажите, что это именно оно, используя конструкцию CROSS JOIN.
Для оптимизатора запроса может быть и без разницы как вы реализуете соединение (при помощи WHERE или JOIN), он их может выполнить абсолютно одинаково. Но из соображения понимаемости кода, я бы рекомендовал в современных СУБД стараться никогда не делать соединение таблиц при помощи WHERE-условия. Использовать WHERE-условия для соединения, в том случае, если в СУБД реализованы конструкции JOIN, я бы назвал сейчас моветоном. WHERE-условия служат для фильтрации набора, и не нужно перемешивать условия служащие для соединения, с условиями отвечающими за фильтрацию. Но если вы пришли к выводу, что без реализации соединения через WHERE не обойтись, то конечно приоритет за решеной задачей и «к черту все устои».
UNION-объединения – операции вертикального объединения результатов запросов
Я специально использую словосочетания горизонтальное соединение и вертикальное объединение, т.к. заметил, что новички часто недопонимают и путают суть этих операций.
Давайте первым делом вспомним как мы делали первую версию отчета для директора:
Так вот, если бы мы не знали, что существует операция группировки, но знали бы, что существует операция объединения результатов запроса при помощи UNION ALL, то мы могли бы склеить все эти запросы следующим образом:
Т.е. UNION ALL позволяет склеить результаты, полученные разными запросами в один общий результат.
Соответственно количество колонок в каждом запросе должно быть одинаковым, а также должны быть совместимыми и типы этих колонок, т.е. строка под строкой, число под числом, дата под датой и т.п.
Немного теории
В MS SQL реализованы следующие виды вертикального объединения:
| Операция | Описание |
|---|---|
| UNION ALL | В результат включаются все строки из обоих наборов. (A+B) |
| UNION | В результат включаются только уникальные строки двух наборов. DISTINCT(A+B) |
| EXCEPT | В результат попадают уникальные строки верхнего набора, которые отсутствуют в нижнем наборе. Разница 2-х множеств. DISTINCT(A-B) |
| INTERSECT | В результат включаются только уникальные строки, присутствующие в обоих наборах. Пересечение 2-х множеств. DISTINCT(A&B) |
Все это проще понять на наглядном примере.
Создадим 2 таблицы и наполним их данными:
Посмотрим на содержимое:
| T1 | T2 |
|---|---|
| 1 | Text 1 |
| 1 | Text 1 |
| 2 | Text 2 |
| 3 | Text 3 |
| 4 | Text 4 |
| 5 | Text 5 |
| B1 | B2 |
|---|---|
| 2 | Text 2 |
| 3 | Text 3 |
| 6 | Text 6 |
| 6 | Text 6 |
UNION ALL
UNION
По сути UNION можно представить, как UNION ALL, к которому применена операция DISTINCT:


