О потоках в процессоре
Добрый день. Сегодня хотелось бы разобрать, что такое потоки в процессоре. Те самые, о функциях и возможностях которых большинство и не догадывается, однако любят хвастаться остальным.

Если провести сравнение процессоров разных поколений, то можно заметить одну интересную тенденцию: многопоточность – штука полезная и здорово повышает суммарную производительность системы.
Начнем с того, что каждый современный процессор построен на физических ядрах с определенной частотой. Допустим, 1 ядро имеет тактовую частоту в 3 ГГц, т.е. может выполнить 3 млрд вычислительных операций за секунду (такт). Но современные ОС (Windows, Linux, MacOS) запускают более 3 млрд процессов, т.е. пользователь начинает сталкиваться с таким понятием как прерывание: ЦП физически не успевает обрабатывать все сразу и начинает переключаться на самые приоритетные задачи.
Логика здесь элементарная: присмотреться к многоядерным и многопоточным решениям. Разгон не дает линейного прироста в производительности, иначе такие гиганты как Intel и AMD выпускали бы процессоры на 5-6 и более ГГц.
Польза от повышения частоты есть, но она нивелируется увеличенным энергопотреблением и сокращением срока службы ЦП.
Многопоточность и все о ней
Многие наверняка слышали выражения из серии «2 потока», «4 потока», «8 потоков» и т.д. При этом физических ядер зачастую было в 2 раза меньше.
Эта технология имеет название HyperThreading (Intel) или SMT (AMD).
Многопоточность у красных появилась совсем недавно, с выходом чипов Ryzen на совершенно новом техпроцессе. Что это такое – тема отдельной статьи.
Цель функции заключается в том, что на 1 ядро может одновременно обрабатывать несколько потоков данных. Пока первый поток простаивает, а второй занимается вычислением, запущенное приложение может воспользоваться вакантной логической мощью для своих целей. В результате, прерывания случаются гораздо реже, а вы не ощущаете тормозов и прочих неудобств при работе.
Недостаток технологии заключается в следующем:
 Если очень грубо, то все кирпичи с одного места на другое можно перенести в одной руке (1 поток), либо в двух (2 потока), но человек при этом один (1 ядро) и устает одинаково при любых условиях, хоть его производительность фактически увеличивается вдвое. Иными словами, мы упираемся в производительность ЦП, а конкретней в его частоту.
Если очень грубо, то все кирпичи с одного места на другое можно перенести в одной руке (1 поток), либо в двух (2 потока), но человек при этом один (1 ядро) и устает одинаково при любых условиях, хоть его производительность фактически увеличивается вдвое. Иными словами, мы упираемся в производительность ЦП, а конкретней в его частоту.
Знакомы с понятием Turbo Boost? Процесс кратковременно повышает частоту процессора на несколько сотен мегагерц в особо сложных сценариях, чтобы вы не испытывали проблем при обработке сложных данных.
Сколько нужно ядер и потоков современному обывателю?
Как я уже сказал выше, современные ОС падки на ресурсы процессора, поскольку отнимают часть мощностей на собственные службы, интерфейс, красивости и функции защиты в реальном времени. Но при этом пользователь хочет еще и работать с комфортом.

Вместо итогов
Практика показывает, что современный универсальный ПК должен иметь в своем распоряжении как минимум 4 ядра/8 потоков, чего будет достаточно для большинства задач, связанных с обработкой данных. Хотя варианты из серии 6/12 выглядят более обещающими по той причине, что стоят они не намного дороже, а пользы от них больше.
В качестве «золотой» середины можем предложить свежий вариант модели, построенный на обновленной архитектуре Zen2. Он отлично справляется с играми, программами, распараллеливанием и обработкой данных, при этом отлично гонится(одним словом — стал популярным (появился в июле 2019)).
Надеемся, что вы почерпнули для себя полезную информацию, которая пригодится при подборе процессора для будущей системы. Следите за дальнейшими обновлениями, чтобы не пропустить новые статьи об анатомии ЦП.
Внутри процесса: многопоточность и пинг-понг mutex’ом


Какая тема вызывает больше всего вопросов и затруднений у начинающих? Когда я спросила об этом преподавателя и Java-программиста Александра Пряхина, он сразу ответил: «Многопоточность». Спасибо ему за идею и помощь в подготовке этой статьи!
Мы заглянем во внутренний мир приложения и его процессов, разберёмся, в чём суть многопоточности, когда она полезна и как её реализовать — на примере Java. Если учите другой язык ООП, не огорчайтесь: базовые принципы одни и те же.
О потоках и их истоках
Чтобы понять многопоточность, сначала вникнем, что такое процесс. Процесс – это часть виртуальной памяти и ресурсов, которую ОС выделяет для выполнения программы. Если открыть несколько экземпляров одного приложения, под каждый система выделит по процессу. В современных браузерах за каждую вкладку может отвечать отдельный процесс.
Вы наверняка сталкивались с «Диспетчером задач» Windows (в Linux это — «Системный монитор») и знаете, что лишние запущенные процессы грузят систему, а самые «тяжёлые» из них часто зависают, так что их приходится завершать принудительно.
Но пользователи любят многозадачность: хлебом не корми — дай открыть с десяток окон и попрыгать туда-сюда. Налицо дилемма: нужно обеспечить одновременную работу приложений и при этом снизить нагрузку на систему, чтобы она не тормозила. Допустим, «железу» не угнаться за потребностями владельцев — нужно решать вопрос на программном уровне.
Мы хотим, чтобы в единицу времени процессор успевал выполнить больше команд и обработать больше данных. То есть нам надо уместить в каждом кванте времени больше выполненного кода. Представьте единицу выполнения кода в виде объекта — это и есть поток.
К сложному делу легче подступиться, если разбить его на несколько простых. Так и при работе с памятью: «тяжёлый» процесс делят на потоки, которые занимают меньше ресурсов и скорее доносят код до вычислителя (как именно — см. ниже).
У каждого приложения есть как минимум один процесс, а у каждого процесса — минимум один поток, который называют главным и из которого при необходимости запускают новые.
Разница между потоками и процессами
Потоки используют память, выделенную под процесс, а процессы требуют себе отдельное место в памяти. Поэтому потоки создаются и завершаются быстрее: системе не нужно каждый раз выделять им новое адресное пространство, а потом высвобождать его.
Процессы работают каждый со своими данными — обмениваться чем-то они могут только через механизм межпроцессного взаимодействия. Потоки обращаются к данным и ресурсам друг друга напрямую: что изменил один — сразу доступно всем. Поток может контролировать «собратьев» по процессу, в то время как процесс контролирует исключительно своих «дочек». Поэтому переключаться между потоками быстрее и коммуникация между ними организована проще.
Какой отсюда вывод? Если вам нужно как можно быстрее обработать большой объём данных, разбейте его на куски, которые можно обрабатывать отдельными потоками, а затем соберите результат воедино. Это лучше, чем плодить жадные до ресурсов процессы.
Но почему такое популярное приложение как Firefox идёт по пути создания нескольких процессов? Потому что именно для браузера изолированная работа вкладок — это надёжно и гибко. Если с одним процессом что-то не так, не обязательно завершать программу целиком — есть возможность сохранить хотя бы часть данных.
Что такое многопоточность
Вот мы и подошли к главному. Многопоточность — это когда процесс приложения разбит на потоки, которые параллельно — в одну единицу времени — обрабатываются процессором.
Вычислительная нагрузка распределяется между двумя или более ядрами, так что интерфейс и другие компоненты программы не замедляют работу друг друга.
Многопоточные приложения можно запускать и на одноядерных процессорах, но тогда потоки выполняются по очереди: первый поработал, его состояние сохранили — дали поработать второму, сохранили — вернулись к первому или запустили третий, и т.д.

Занятые люди жалуются, что у них всего две руки. Процессы и программы могут иметь столько рук, сколько нужно для скорейшего выполнения задачи.
Жди сигнала: синхронизация в многопоточных приложениях
Представьте, что несколько потоков пытаются одновременно изменить одну и ту же область данных. Чьи изменения будут в итоге приняты, а чьи — отменены? Чтобы работа с общими ресурсами не приводила к путанице, потокам нужно координировать свои действия. Для этого они обмениваются информацией с помощью сигналов. Каждый поток сообщает другим, что он сейчас делает и каких изменений ждать. Так данные всех потоков о текущем состоянии ресурсов синхронизируются.
В категориях объектно-ориентированного программирования сигналы — это объекты синхронизации. У каждого из них — своя роль во взаимодействии.
Основные средства синхронизации
Взаимоисключение (mutual exclusion, сокращённо — mutex) — «флажок», переходящий к потоку, который в данный момент имеет право работать с общими ресурсами. Исключает доступ остальных потоков к занятому участку памяти. Мьютексов в приложении может быть несколько, и они могут разделяться между процессами. Есть подвох: mutex заставляет приложение каждый раз обращаться к ядру операционной системы, что накладно.
Семафор — позволяет вам ограничить число потоков, имеющих доступ к ресурсу в конкретный момент. Так вы снизите нагрузку на процессор при выполнении кода, где есть узкие места. Проблема в том, что оптимальное число потоков зависит от машины пользователя.
Событие — вы определяете условие, при наступлении которого управление передаётся нужному потоку. Данными о событиях потоки обмениваются, чтобы развивать и логически продолжать действия друг друга. Один получил данные, другой проверил их корректность, третий — сохранил на жёсткий диск. События различаются по способу отмены сигнала о них. Если нужно уведомить о событии несколько потоков, для остановки сигнала придётся вручную ставить функцию отмены. Если же целевой поток только один, можно создать событие с автоматическим сбросом. Оно само остановит сигнал, после того как он дойдёт до потока. Для гибкого управления потоками события можно выстраивать в очередь.
Критическая секция — более сложный механизм, который объединяет в себе счётчик цикла и семафор. Счётчик позволяет отложить запуск семафора на нужное время. Преимущество в том, что ядро задействуется лишь в случае, если секция занята и нужно включать семафор. В остальное время поток выполняется в пользовательском режиме. Увы, секцию можно использовать только внутри одного процесса.
Как реализовать многопоточность в Java
За работу с потоками в Java отвечает класс Thread. Создать новый поток для выполнения задачи — значит создать экземпляр класса Thread и связать его с нужным кодом. Сделать это можно двумя путями:
образовать от Thread подкласс;
имплементировать в своём классе интерфейс Runnable, после чего передавать экземпляры класса в конструктор Thread.
Пока мы не будем затрагивать тему тупиковых ситуаций (deadlock’ов), когда потоки блокируют работу друг друга и зависают — оставим это для следующей статьи. А сейчас перейдём к практике.
Пример многопоточности в Java: пинг-понг мьютексами
Если вы думаете, что сейчас будет что-то страшное — выдохните. Работу с объектами синхронизации мы рассмотрим почти в игровой форме: два потока будут перебрасываться mutex’ом. Но по сути вы увидите реальное приложение, где в один момент времени только один поток может обрабатывать общедоступные данные.
Сначала создадим класс, наследующий свойства уже известного нам Thread, и напишем метод «удара по мячу» (kickBall):
Теперь позаботимся о мячике. Будет он у нас не простой, а памятливый: чтоб мог рассказать, кто по нему ударил, с какой стороны и сколько раз. Для этого используем mutex: он будет собирать информацию о работе каждого из потоков — это позволит изолированным потокам общаться друг с другом. После 15-го удара выведем мяч из игры, чтоб его сильно не травмировать.
А теперь на сцену выходят два потока-игрока. Назовём их, не мудрствуя лукаво, Пинг и Понг:
«Полный стадион народа — время начинать матч». Объявим об открытии встречи официально — в главном классе приложения:
Как видите, ничего зубодробительного здесь нет. Это пока только введение в многопоточность, но вы уже представляете, как это работает, и можете экспериментировать — ограничивать длительность игры не числом ударов, а по времени, например. Мы ещё вернёмся к теме многопоточности — рассмотрим пакет java.util.concurrent, библиотеку Akka и механизм volatile. А еще поговорим о реализации многопоточности на Python.
Какая тема вызывает больше всего вопросов и затруднений у начинающих? Когда я спросила об этом преподавателя и Java-программиста Александра Пряхина, он сразу ответил: «Многопоточность». Спасибо ему за идею и помощь в подготовке этой статьи!
Мы заглянем во внутренний мир приложения и его процессов, разберёмся, в чём суть многопоточности, когда она полезна и как её реализовать — на примере Java. Если учите другой язык ООП, не огорчайтесь: базовые принципы одни и те же.
О потоках и их истоках
Чтобы понять многопоточность, сначала вникнем, что такое процесс. Процесс – это часть виртуальной памяти и ресурсов, которую ОС выделяет для выполнения программы. Если открыть несколько экземпляров одного приложения, под каждый система выделит по процессу. В современных браузерах за каждую вкладку может отвечать отдельный процесс.
Вы наверняка сталкивались с «Диспетчером задач» Windows (в Linux это — «Системный монитор») и знаете, что лишние запущенные процессы грузят систему, а самые «тяжёлые» из них часто зависают, так что их приходится завершать принудительно.
Но пользователи любят многозадачность: хлебом не корми — дай открыть с десяток окон и попрыгать туда-сюда. Налицо дилемма: нужно обеспечить одновременную работу приложений и при этом снизить нагрузку на систему, чтобы она не тормозила. Допустим, «железу» не угнаться за потребностями владельцев — нужно решать вопрос на программном уровне.
Мы хотим, чтобы в единицу времени процессор успевал выполнить больше команд и обработать больше данных. То есть нам надо уместить в каждом кванте времени больше выполненного кода. Представьте единицу выполнения кода в виде объекта — это и есть поток.
К сложному делу легче подступиться, если разбить его на несколько простых. Так и при работе с памятью: «тяжёлый» процесс делят на потоки, которые занимают меньше ресурсов и скорее доносят код до вычислителя (как именно — см. ниже).
У каждого приложения есть как минимум один процесс, а у каждого процесса — минимум один поток, который называют главным и из которого при необходимости запускают новые.
Разница между потоками и процессами
Потоки используют память, выделенную под процесс, а процессы требуют себе отдельное место в памяти. Поэтому потоки создаются и завершаются быстрее: системе не нужно каждый раз выделять им новое адресное пространство, а потом высвобождать его.
Процессы работают каждый со своими данными — обмениваться чем-то они могут только через механизм межпроцессного взаимодействия. Потоки обращаются к данным и ресурсам друг друга напрямую: что изменил один — сразу доступно всем. Поток может контролировать «собратьев» по процессу, в то время как процесс контролирует исключительно своих «дочек». Поэтому переключаться между потоками быстрее и коммуникация между ними организована проще.
Какой отсюда вывод? Если вам нужно как можно быстрее обработать большой объём данных, разбейте его на куски, которые можно обрабатывать отдельными потоками, а затем соберите результат воедино. Это лучше, чем плодить жадные до ресурсов процессы.
Но почему такое популярное приложение как Firefox идёт по пути создания нескольких процессов? Потому что именно для браузера изолированная работа вкладок — это надёжно и гибко. Если с одним процессом что-то не так, не обязательно завершать программу целиком — есть возможность сохранить хотя бы часть данных.
Что такое многопоточность
Вот мы и подошли к главному. Многопоточность — это когда процесс приложения разбит на потоки, которые параллельно — в одну единицу времени — обрабатываются процессором.
Вычислительная нагрузка распределяется между двумя или более ядрами, так что интерфейс и другие компоненты программы не замедляют работу друг друга.
Многопоточные приложения можно запускать и на одноядерных процессорах, но тогда потоки выполняются по очереди: первый поработал, его состояние сохранили — дали поработать второму, сохранили — вернулись к первому или запустили третий, и т.д.
Занятые люди жалуются, что у них всего две руки. Процессы и программы могут иметь столько рук, сколько нужно для скорейшего выполнения задачи.
Жди сигнала: синхронизация в многопоточных приложениях
Представьте, что несколько потоков пытаются одновременно изменить одну и ту же область данных. Чьи изменения будут в итоге приняты, а чьи — отменены? Чтобы работа с общими ресурсами не приводила к путанице, потокам нужно координировать свои действия. Для этого они обмениваются информацией с помощью сигналов. Каждый поток сообщает другим, что он сейчас делает и каких изменений ждать. Так данные всех потоков о текущем состоянии ресурсов синхронизируются.
В категориях объектно-ориентированного программирования сигналы — это объекты синхронизации. У каждого из них — своя роль во взаимодействии.
Основные средства синхронизации
Взаимоисключение (mutual exclusion, сокращённо — mutex) — «флажок», переходящий к потоку, который в данный момент имеет право работать с общими ресурсами. Исключает доступ остальных потоков к занятому участку памяти. Мьютексов в приложении может быть несколько, и они могут разделяться между процессами. Есть подвох: mutex заставляет приложение каждый раз обращаться к ядру операционной системы, что накладно.
Семафор — позволяет вам ограничить число потоков, имеющих доступ к ресурсу в конкретный момент. Так вы снизите нагрузку на процессор при выполнении кода, где есть узкие места. Проблема в том, что оптимальное число потоков зависит от машины пользователя.
Событие — вы определяете условие, при наступлении которого управление передаётся нужному потоку. Данными о событиях потоки обмениваются, чтобы развивать и логически продолжать действия друг друга. Один получил данные, другой проверил их корректность, третий — сохранил на жёсткий диск. События различаются по способу отмены сигнала о них. Если нужно уведомить о событии несколько потоков, для остановки сигнала придётся вручную ставить функцию отмены. Если же целевой поток только один, можно создать событие с автоматическим сбросом. Оно само остановит сигнал, после того как он дойдёт до потока. Для гибкого управления потоками события можно выстраивать в очередь.
Критическая секция — более сложный механизм, который объединяет в себе счётчик цикла и семафор. Счётчик позволяет отложить запуск семафора на нужное время. Преимущество в том, что ядро задействуется лишь в случае, если секция занята и нужно включать семафор. В остальное время поток выполняется в пользовательском режиме. Увы, секцию можно использовать только внутри одного процесса.
Как реализовать многопоточность в Java
За работу с потоками в Java отвечает класс Thread. Создать новый поток для выполнения задачи — значит создать экземпляр класса Thread и связать его с нужным кодом. Сделать это можно двумя путями:
образовать от Thread подкласс;
имплементировать в своём классе интерфейс Runnable, после чего передавать экземпляры класса в конструктор Thread.
Пока мы не будем затрагивать тему тупиковых ситуаций (deadlock’ов), когда потоки блокируют работу друг друга и зависают — оставим это для следующей статьи. А сейчас перейдём к практике.
Пример многопоточности в Java: пинг-понг мьютексами
Если вы думаете, что сейчас будет что-то страшное — выдохните. Работу с объектами синхронизации мы рассмотрим почти в игровой форме: два потока будут перебрасываться mutex’ом. Но по сути вы увидите реальное приложение, где в один момент времени только один поток может обрабатывать общедоступные данные.
Сначала создадим класс, наследующий свойства уже известного нам Thread, и напишем метод «удара по мячу» (kickBall):
Теперь позаботимся о мячике. Будет он у нас не простой, а памятливый: чтоб мог рассказать, кто по нему ударил, с какой стороны и сколько раз. Для этого используем mutex: он будет собирать информацию о работе каждого из потоков — это позволит изолированным потокам общаться друг с другом. После 15-го удара выведем мяч из игры, чтоб его сильно не травмировать.
А теперь на сцену выходят два потока-игрока. Назовём их, не мудрствуя лукаво, Пинг и Понг:
«Полный стадион народа — время начинать матч». Объявим об открытии встречи официально — в главном классе приложения:
Процессоры, ядра и потоки. Топология систем
В этой статье я попытаюсь описать терминологию, используемую для описания систем, способных исполнять несколько программ параллельно, то есть многоядерных, многопроцессорных, многопоточных. Разные виды параллелизма в ЦПУ IA-32 появлялись в разное время и в несколько непоследовательном порядке. Во всём этом довольно легко запутаться, особенно учитывая, что операционные системы заботливо прячут детали от не слишком искушённых прикладных программ.

Используемая далее терминология используется в документации процессорам Intel. Другие архитектуры могут иметь другие названия для похожих понятий. Там, где они мне известны, я буду их упоминать.
Цель статьи — показать, что при всём многообразии возможных конфигураций многопроцессорных, многоядерных и многопоточных систем для программ, исполняющихся на них, создаются возможности как для абстракции (игнорирования различий), так и для учёта специфики (возможность программно узнать конфигурацию).
Процессор
Конечно же, самый древний, чаще всего используемый и неоднозначный термин — это «процессор».
В современном мире процессор — это то (package), что мы покупаем в красивой Retail коробке или не очень красивом OEM-пакетике. Неделимая сущность, вставляемая в разъём (socket) на материнской плате. Даже если никакого разъёма нет и снять его нельзя, то есть если он намертво припаян, это один чип.

Мобильные системы (телефоны, планшеты, ноутбуки) и большинство десктопов имеют один процессор. Рабочие станции и сервера иногда могут похвастаться двумя или больше процессорами на одной материнской плате.
Поддержка нескольких центральных процессоров в одной системе требует многочисленных изменений в её дизайне. Как минимум, необходимо обеспечить их физическое подключение (предусмотреть несколько сокетов на материнской плате), решить вопросы идентификации процессоров (см. далее в этой статье, а также мою предыдущую заметку), согласования доступов к памяти и доставки прерываний (контроллер прерываний должен уметь маршрутизировать прерывания на несколько процессоров) и, конечно же, поддержки со стороны операционной системы. Я, к сожалению, не смог найти документального упоминания момента создания первой многопроцессорной системы на процессорах Intel, однако Википедия утверждает, что Sequent Computer Systems поставляла их уже в 1987 году, используя процессоры Intel 80386. Широко распространённой поддержка же нескольких чипов в одной системе становится доступной, начиная с Intel® Pentium.
Если процессоров несколько, то каждый из них имеет собственный разъём на плате. У каждого из них при этом имеются полные независимые копии всех ресурсов, таких как регистры, исполняющие устройства, кэши. Делят они общую память — RAM. Память может подключаться к ним различными и довольно нетривиальными способами, но это отдельная история, выходящая за рамки этой статьи. Важно то, что при любом раскладе для исполняемых программ должна создаваться иллюзия однородной общей памяти, доступной со всех входящих в систему процессоров.

К взлёту готов! Intel® Desktop Board D5400XS
Исторически многоядерность в Intel IA-32 появилась позже Intel® HyperThreading, однако в логической иерархии она идёт следующей.
Казалось бы, если в системе больше процессоров, то выше её производительность (на задачах, способных задействовать все ресурсы). Однако, если стоимость коммуникаций между ними слишком велика, то весь выигрыш от параллелизма убивается длительными задержками на передачу общих данных. Именно это наблюдается в многопроцессорных системах — как физически, так и логически они находятся очень далеко друг от друга. Для эффективной коммуникации в таких условиях приходится придумывать специализированные шины, такие как Intel® QuickPath Interconnect. Энергопотребление, размеры и цена конечного решения, конечно, от всего этого не понижаются. На помощь должна прийти высокая интеграция компонент — схемы, исполняющие части параллельной программы, надо подтащить поближе друг к другу, желательно на один кристалл. Другими словами, в одном процессоре следует организовать несколько ядер, во всём идентичных друг другу, но работающих независимо.
Первые многоядерные процессоры IA-32 от Intel были представлены в 2005 году. С тех пор среднее число ядер в серверных, десктопных, а ныне и мобильных платформах неуклонно растёт.
В отличие от двух одноядерных процессоров в одной системе, разделяющих только память, два ядра могут иметь также общие кэши и другие ресурсы, отвечающие за взаимодействие с памятью. Чаще всего кэши первого уровня остаются приватными (у каждого ядра свой), тогда как второй и третий уровень может быть как общим, так и раздельным. Такая организация системы позволяет сократить задержки доставки данных между соседними ядрами, особенно если они работают над общей задачей.
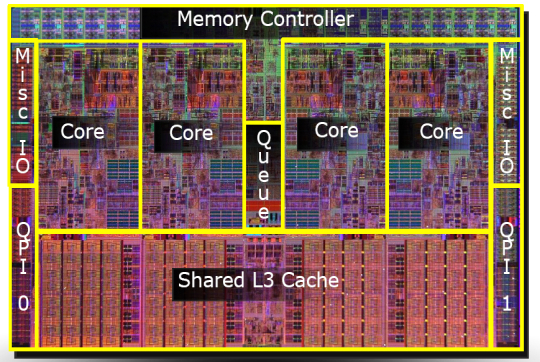
Микроснимок четырёхядерного процессора Intel с кодовым именем Nehalem. Выделены отдельные ядра, общий кэш третьего уровня, а также линки QPI к другим процессорам и общий контроллер памяти.
Гиперпоток
До примерно 2002 года единственный способ получить систему IA-32, способную параллельно исполнять две или более программы, состоял в использовании именно многопроцессорных систем. В Intel® Pentium® 4, а также линейке Xeon с кодовым именем Foster (Netburst) была представлена новая технология — гипертреды или гиперпотоки, — Intel® HyperThreading (далее HT).
Ничто не ново под луной. HT — это частный случай того, что в литературе именуется одновременной многопоточностью (simultaneous multithreading, SMT). В отличие от «настоящих» ядер, являющихся полными и независимыми копиями, в случае HT в одном процессоре дублируется лишь часть внутренних узлов, в первую очередь отвечающих за хранение архитектурного состояния — регистры. Исполнительные же узлы, ответственные за организацию и обработку данных, остаются в единственном числе, и в любой момент времени используются максимум одним из потоков. Как и ядра, гиперпотоки делят между собой кэши, однако начиная с какого уровня — это зависит от конкретной системы.
Я не буду пытаться объяснить все плюсы и минусы дизайнов с SMT вообще и с HT в частности. Интересующийся читатель может найти довольно подробное обсуждение технологии во многих источниках, и, конечно же, в Википедии. Однако отмечу следующий важный момент, объясняющий текущие ограничения на число гиперпотоков в реальной продукции.
Ограничения потоков
В каких случаях наличие «нечестной» многоядерности в виде HT оправдано? Если один поток приложения не в состоянии загрузить все исполняющие узлы внутри ядра, то их можно «одолжить» другому потоку. Это типично для приложений, имеющих «узкое место» не в вычислениях, а при доступе к данным, то есть часто генерирующих промахи кэша и вынужденных ожидать доставку данных из памяти. В это время ядро без HT будет вынуждено простаивать. Наличие же HT позволяет быстро переключить свободные исполняющие узлы к другому архитектурному состоянию (т.к. оно как раз дублируется) и исполнять его инструкции. Это — частный случай приёма под названием latency hiding, когда одна длительная операция, в течение которой полезные ресурсы простаивают, маскируется параллельным выполнением других задач. Если приложение уже имеет высокую степень утилизации ресурсов ядра, наличие гиперпотоков не позволит получить ускорение — здесь нужны «честные» ядра.
Типичные сценарии работы десктопных и серверных приложений, рассчитанных на машинные архитектуры общего назначения, имеют потенциал к параллелизму, реализуемому с помощью HT. Однако этот потенциал быстро «расходуется». Возможно, по этой причине почти на всех процессорах IA-32 число аппаратных гиперпотоков не превышает двух. На типичных сценариях выигрыш от использования трёх и более гиперпотоков был бы невелик, а вот проигрыш в размере кристалла, его энергопотреблении и стоимости значителен.
Другая ситуация наблюдается на типичных задачах, выполняемых на видеоускорителях. Поэтому для этих архитектур характерно использование техники SMT с бóльшим числом потоков. Так как сопроцессоры Intel® Xeon Phi (представленные в 2010 году) идеологически и генеалогически довольно близки к видеокартам, на них может быть четыре гиперпотока на каждом ядре — уникальная для IA-32 конфигурация.
Логический процессор
Из трёх описанных «уровней» параллелизма (процессоры, ядра, гиперпотоки) в конкретной системе могут отсутствовать некоторые или даже все. На это влияют настройки BIOS (многоядерность и многопоточность отключаются независимо), особенности микроархитектуры (например, HT отсутствовал в Intel® Core™ Duo, но был возвращён с выпуском Nehalem) и события при работе системы (многопроцессорные сервера могут выключать отказавшие процессоры в случае обнаружения неисправностей и продолжать «лететь» на оставшихся). Каким образом этот многоуровневый зоопарк параллелизма виден операционной системе и, в конечном счёте, прикладным приложениям?
Далее для удобства обозначим количества процессоров, ядер и потоков в некоторой системе тройкой (x, y, z), где x — это число процессоров, y — число ядер в каждом процессоре, а z — число гиперпотоков в каждом ядре. Далее я буду называть эту тройку топологией — устоявшийся термин, мало что имеющий с разделом математики. Произведение p = xyz определяет число сущностей, именуемых логическими процессорами системы. Оно определяет полное число независимых контекстов прикладных процессов в системе с общей памятью, исполняющихся параллельно, которые операционная система вынуждена учитывать. Я говорю «вынуждена», потому что она не может управлять порядком исполнения двух процессов, находящихся на различных логических процессорах. Это относится в том числе к гиперпотокам: хотя они и работают «последовательно» на одном ядре, конкретный порядок диктуется аппаратурой и недоступен для наблюдения или управления программам.
Чаще всего операционная система прячет от конечных приложений особенности физической топологии системы, на которой она запущена. Например, три следующие топологии: (2, 1, 1), (1, 2, 1) и (1, 1, 2) — ОС будет представлять в виде двух логических процессоров, хотя первая из них имеет два процессора, вторая — два ядра, а третья — всего лишь два потока.
Windows Task Manager показывает 8 логических процессоров; но сколько это в процессорах, ядрах и гиперпотоках?
Linux top показывает 4 логических процессора.
Это довольно удобно для создателей прикладных приложений — им не приходится иметь дело с зачастую несущественными для них особенностями аппаратуры.
Программное определение топологии
Конечно, абстрагирование топологии в единственное число логических процессоров в ряде случаев создаёт достаточно оснований для путаницы и недоразумений (в жарких Интернет-спорах). Вычислительные приложения, желающие выжать из железа максимум производительности, требуют детального контроля над тем, где будут размещены их потоки: поближе друг к другу на соседних гиперпотоках или же наоборот, подальше на разных процессорах. Скорость коммуникаций между логическими процессорами в составе одного ядра или процессора значительно выше, чем скорость передачи данных между процессорами. Возможность неоднородности в организации оперативной памяти также усложняет картину.
Информация о топологии системы в целом, а также положении каждого логического процессора в IA-32 доступна с помощью инструкции CPUID. С момента появления первых многопроцессорных систем схема идентификации логических процессоров несколько раз расширялась. К настоящему моменту её части содержатся в листах 1, 4 и 11 CPUID. Какой из листов следует смотреть, можно определить из следующей блок-схемы, взятой из статьи [2]:
Я не буду здесь утомлять всеми подробностями отдельных частей этого алгоритма. Если возникнет интерес, то этому можно посвятить следующую часть этой статьи. Отошлю интересующегося читателя к [2], в которой этот вопрос разбирается максимально подробно. Здесь же я сначала кратко опишу, что такое APIC и как он связан с топологией. Затем рассмотрим работу с листом 0xB (одиннадцать в десятичном счислении), который на настоящий момент является последним словом в «апикостроении».
APIC ID
В настоящий момент ширина числа, хранящегося в APIC ID, достигла полных 32 бит, хотя в прошлом оно было ограничено 16, а ещё раньше — только 8 битами. Нынче остатки старых дней раскиданы по всему CPUID, однако в CPUID.0xB.EDX[31:0] возвращаются все 32 бита APIC ID. На каждом логическом процессоре, независимо исполняющем инструкцию CPUID, возвращаться будет своё значение.
Выяснение родственных связей
Значение APIC ID само по себе ничего не говорит о топологии. Чтобы узнать, какие два логических процессора находятся внутри одного физического (т.е. являются «братьями» гипертредами), какие два — внутри одного процессора, а какие оказались и вовсе в разных процессорах, надо сравнить их значения APIC ID. В зависимости от степени родства некоторые их биты будут совпадать. Эта информация содержится в подлистьях CPUID.0xB, которые кодируются с помощью операнда в ECX. Каждый из них описывает положение битового поля одного из уровней топологии в EAX[5:0] (точнее, число бит, которые нужно сдвинуть в APIC ID вправо, чтобы убрать нижние уровни топологии), а также тип этого уровня — гиперпоток, ядро или процессор, — в ECX[15:8].
У логических процессоров, находящихся внутри одного ядра, будут совпадать все биты APIC ID, кроме принадлежащих полю SMT. Для логических процессоров, находящихся в одном процессоре, — все биты, кроме полей Core и SMT. Поскольку число подлистов у CPUID.0xB может расти, данная схема позволит поддержать описание топологий и с бóльшим числом уровней, если в будущем возникнет необходимость. Более того, можно будет ввести промежуточные уровни между уже существующими.
Важное следствие из организации данной схемы заключается в том, что в наборе всех APIC ID всех логических процессоров системы могут быть «дыры», т.е. они не будут идти последовательно. Например, во многоядерном процессоре с выключенным HT все APIC ID могут оказаться чётными, так как младший бит, отвечающий за кодирование номера гиперпотока, будет всегда нулевым.
Отмечу, что CPUID.0xB — не единственный источник информации о логических процессорах, доступный операционной системе. Список всех процессоров, доступный ей, вместе с их значениями APIC ID, кодируется в таблице MADT ACPI [3, 4].
Операционные системы и топология
Операционные системы предоставляют информацию о топологии логических процессоров приложениям с помощью своих собственных интерфейсов.
В FreeBSD топология сообщается через механизм sysctl в переменной kern.sched.topology_spec в виде XML:
В MS Windows 8 сведения о топологии можно увидеть в диспетчере задач Task Manager.
Также их предоставляет консольная утилита Sysinternals Coreinfo и API вызов GetLogicalProcessorInformation.
Полная картина
Проиллюстрирую ещё раз отношения между понятиями «процессор», «ядро», «гиперпоток» и «логический процессор» на нескольких примерах.
Система (2, 2, 2)
Система (2, 4, 1)
Система (4, 1, 1)
Прочие вопросы
В этот раздел я вынес некоторые курьёзы, возникающие из-за многоуровневой организации логических процессоров.
Как я уже упоминал, кэши в процессоре тоже образуют иерархию, и она довольно сильно связано с топологией ядер, однако не определяется ей однозначно. Для определения того, какие кэши для каких логических процессоров общие, а какие нет, используется вывод CPUID.4 и её подлистов.
Лицензирование
Некоторые программные продукты поставляются числом лицензий, определяемых количеством процессоров в системе, на которой они будут использоваться. Другие — числом ядер в системе. Наконец, для определения числа лицензий число процессоров может умножаться на дробный «core factor», зависящий от типа процессора!
Виртуализация
Системы виртуализации, способные моделировать многоядерные системы, могут назначить виртуальным процессорам внутри машины произвольную топологию, не совпадающую с конфигурацией реальной аппаратуры. Так, внутри хозяйской системы (1, 2, 2) некоторые известные системы виртуализации по умолчанию выносят все логические процессоры на верхний уровень, т.е. создают конфигурацию (4, 1, 1). В сочетании с особенностями лицензирования, зависящими от топологии, это может порождать забавные эффекты.


