«Вкалывают роботы»: что такое robots.txt и как его настроить
Знание о том, что такое robots.txt, и умение с ним работать больше относится к профессии вебмастера. Однако SEO-специалист — это универсальный мастер, который должен обладать знаниями из разных профессий в сфере IT. Поэтому сегодня разбираемся в предназначении и настройке файла robots.txt.
По факту robots.txt — это текстовый файл, который управляет доступом к содержимому сайтов. Редактировать его можно на своем компьютере в программе Notepad++ или непосредственно на хостинге.
Что такое robots.txt
Представим robots.txt в виде настоящего робота. Когда в гости к вашему сайту приходят поисковые роботы, они общаются именно с robots.txt. Он их встречает и рассказывает, куда можно заходить, а куда нельзя. Если вы дадите команду, чтобы он никого не пускал, так и произойдет, т.е. сайт не будет допущен к индексации.
Если на сайте нет этого файла, создаем его и загружаем на сервер. Его несложно найти, ведь его место в корне сайта. Допишите к адресу сайта /robots.txt и вы увидите его.
Зачем нам нужен этот файл
Если на сайте нет robots.txt, то роботы из поисковых систем блуждают по сайту как им вздумается. Роботы могут залезть в корзину с мусором, после чего у них создастся впечатление, что на вашем сайте очень грязно. robots.txt скрывает от индексации:
Правильно заполненный файл robots.txt создает иллюзию, что на сайте всегда чисто и убрано.
Настройка директивов robots.txt
Директивы — это правила для роботов. И эти правила пишем мы.
User-agent
Пример:
Данное правило смогут понять только те роботы, которые работают в Яндексе. В последнее время эту строчку я заполняю так:
Правило понимает Яндекс и Гугл. Доля трафика с других поисковиков очень мала, и продвигаться в них не стоит затраченных усилий.
Disallow и Allow
С помощью Disallow мы скрываем каталоги от индексации, а, прописывая правило с директивой Allow, даем разрешение на индексацию.
Пример:
Даем рекомендацию, чтобы индексировались категории.
А вот так от индексации будет закрыт весь сайт.
Также существуют операторы, которые помогают уточнить наши правила.
Sitemap
Пример:
Директива host уже устарела, поэтому о ней говорить не будем.
Crawl-delay
Если сайт небольшой, то директиву Crawl-delay заполнять нет необходимости. Эта директива нужна, чтобы задать периодичность скачивания документов с сайта.
Пример:
Это правило означает, что документы с сайта будут скачиваться с интервалом в 10 секунд.
Clean-param
Директива Clean-param закрывает от индексации дубли страниц с разными адресами. Например, если вы продвигаетесь через контекстную рекламу, на сайте будут появляться страницы с utm-метками. Чтобы подобные страницы не плодили дубли, мы можем закрыть их с помощью данной директивы.
Пример:
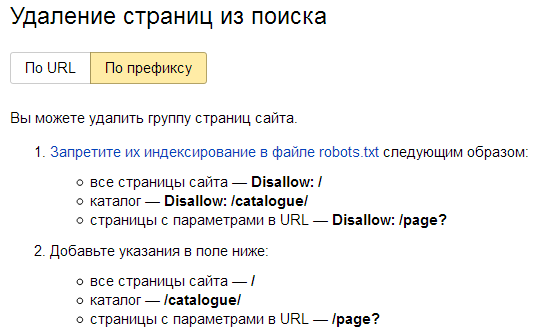
Как закрыть сайт от индексации
Чтобы полностью закрыть сайт от индексации, достаточно прописать в файле следующее:
Если требуется закрыть от поисковиков поддомен, то нужно помнить, что каждому поддомену требуется свой robots.txt. Добавляем файл, если он отсутствует, и прописываем магические символы.
Проверка файла robots
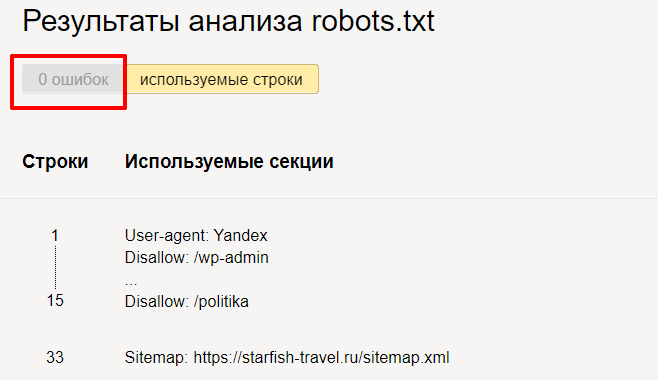
Переходим в инструмент, вводим домен и содержимое вашего файла.
Нажимаем « Проверить » и получаем результаты анализа. Здесь мы можем увидеть, есть ли ошибки в нашем robots.txt.
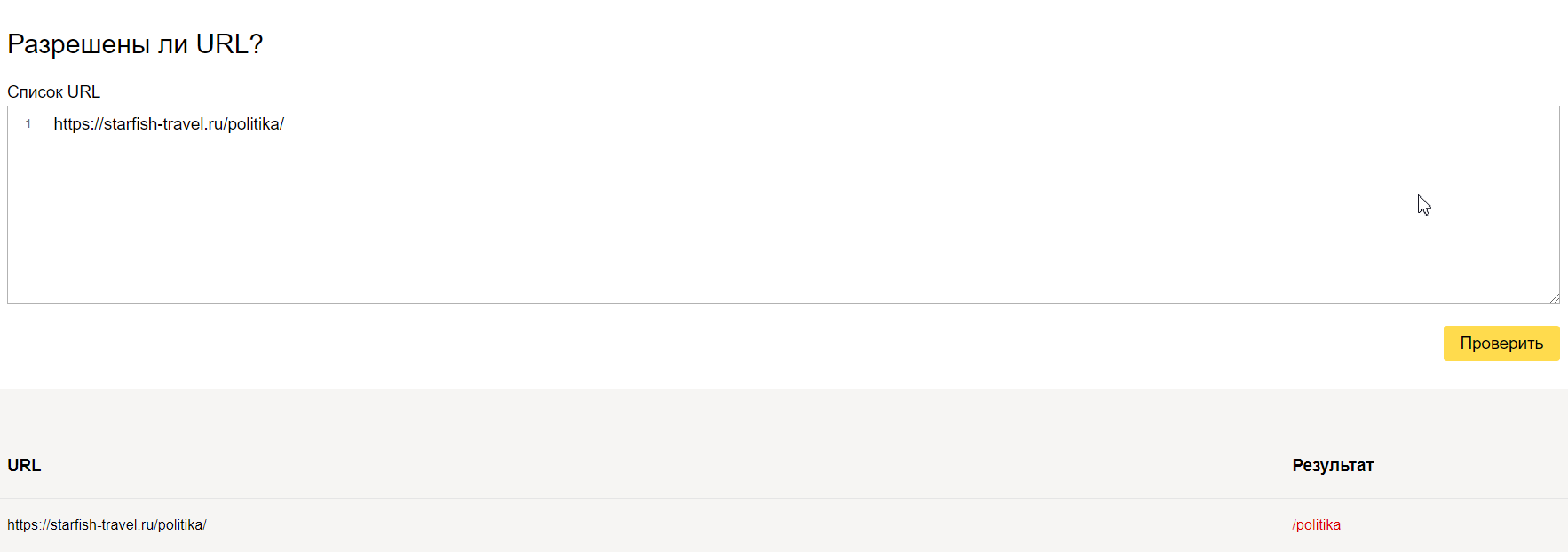
Но на этом функции инструмента не заканчиваются. Вы можете проверить, разрешены ли определенные страницы сайта для индексации или нет.
Здесь вас ждет простор для творчества. Пользуйтесь звездочкой или знаком доллара и закрывайте от индексации страницы, которые не несут пользы для посетителей. Будьте внимательны – проверяйте, не закрыли ли вы от индексации важные страницы.
Правильный robots.txt для WordPress
Кстати, если вы поставите #, то сможете оставлять комментарии, которые не будут учитываться роботами.
Правильный robots.txt для Joomla
Здесь указаны другие названия директорий, но суть одна: закрыть мусорные и служебные страницы, чтобы показать поисковиками только то, что они хотят увидеть.
Продвинутое использование robots.txt без ошибок — руководство для SEO
1 сентября 2019 года Google прекратит поддержку нескольких директив в robots.txt. В список попали: noindex, crawl-delay и nofollow. Вместо них рекомендуется использовать:
404 и 410 коды ответа сервера. В ряде случаев, 410 отрабатывает значительно быстрей для удаления URL из индекса.
Защита паролем. Страницы, требующие авторизации, также обычно удаляются из индекса (важно — именно страницы, полностью скрытые под логином, а не часть контента).
Временное удаление страницы из индекса с помощью инструмента в Search Console.
Disallow в robots.txt.
Тем не менее, robots.txt по-прежнему остаётся одним из главных файлов для SEO-специалиста. Давайте вспомним самые полезные директивы от простых, до менее очевидных.
robots.txt
Это простой текстовый файл, который содержит инструкции для поисковых краулеров — какие страницы сайта не следует посещать, где лежит наш Sitemap.xml и для каких поисковых роботов распространяются правила.
Файл размещается в корневой директории сайта. Например:
Прежде чем начать сканирование сайта, краулеры проверяют наличие robots.txt и находят правила специфичные для их User-Agent, например Googlebot. Если таких нет — следуют общим инструкциям.
Действующие правила robots.txt
User-Agent
У каждой поисковой системы есть свои «агенты пользователя». По сути, это имя краулера, которое помогает дать определённые указания конкретному ему.
Если брать шире, то User-Agent — клиентское приложение на стороне поисковой системы, в некотором смысле имитирующее браузер или, например, мобильное устройство.
User-agent: * — символ астериск используются для обозначения сразу же всех краулеров.
User-agent: Yandex — основной краулер Яндекс-поиска.
User-agent: Google-Image — робот поиска Google по картинкам.
User-agent: AhrefsBot — краулер сервиса Ahrefs.
Важно: если в файле указаны правила для конкретных User-Agent, то роботы будут следовать только своим инструкциям, игнорируя общие правила.
Disallow
Директива, которая позволяет блокировать от индексации полностью весь сайт или определённые разделы.
Может быть полезно для закрытия от сканирования служебных, динамических или временных страниц (символ # отвечает за комментарии в коде и игнорируется краулерами).
Упростить инструкции помогают операторы:
* — любая последовательность символов в URL. По умолчанию к концу каждого правила, описанного в файле robots.txt, приписывается спецсимвол *.
$ — символ в конце URL-адреса, он используется чтобы отменить использование * на конце правила.
Важно: в robots.txt не нужно закрывать JS и CSS-файлы, они понадобятся поисковым роботом для правильного отображения (рендеринга) контента.
Allow
С помощью этой директивы можно, напротив, разрешить каталог или конкретный адрес к индексации. В некоторых случаях проще запретить к сканированию весь сайт и с помощью Allow открыть нужные разделы.
Также Allow можно использовать для отдельных User-Agent.
Crawl-delay
Директива, теряющая актуальность в случае Goolge, но полезная для работы с другими поисковиками.
Позволяет замедлить сканирование, если сервер бывает перегружен. Устанавливает интервал времени для обхода страниц в секундах (для Яндекса). Чем выше значение, тем медленнее краулер ходит по сайту.
Несмотря на то, что Googlebot игнорирует подобные правила, настроить скорость сканирования можно в Google Search Console проекта.
Интересно, что китайский Baidu также не обращает внимание на Crawl-delay в robots.txt, а Bing воспринимает команду как «временное окно», в рамках которого BingBot будет сканировать сайт только один раз.
Важно: если установлено высокое значение Crawl-delay, убедитесь, что ваш сайт своевременно индексируется. В сутках 86 400 секунд, при Crawl-delay: 30 будет просканировано не более 2880 страниц в день, что мало для крупных сайтов.
Sitemap
Одно из ключевых применений robots.txt в SEO — указание на расположение карты сайты. Обратите внимание, используется полный URL-адрес (их может быть несколько).
Нельзя использовать относительный адрес карты сайта, только полный URL.
Файл XML-карты сайта должен располагаться на том же домене.
Также убедитесь, что ссылка возвращает статус 200 OK без редиректов. Проверить можно с помощью инструмента, определяющего ответ сервера или анализа XML-карты сайта.
Типичный robots.txt
Ниже представлены простые и распространенные шаблоны команд для поисковых роботов.
Разрешить полный доступ
Обратите внимание, правило для Disallow в этом случае не заполняется.
Полная блокировка доступа к хосту
Запрет конкретного раздела сайта
Запрет сканирования определенного файла
Распространенная ошибка
Установка индивидуальных правил для User-Agent без дублирования инструкций Disallow.
Как мы уже выяснили, при указании директивы User-Agent, соответствующий краулер будет следовать только тем правилам, что установлены именно для него. Не забывайте дублировать общие директивы для всех User-Agent.
В примере ниже — слегка измененный robots.txt сайта IMDB. Общие правила Disallow не будут распространяться на бот ScoutJet. А вот Crawl-delay, напротив, установлена только для него.
Противоречия директив
Список распространенных User-Agent
User-Agent
#
Google
Googlebot
Основной краулер Google
Googlebot-Image
Робот поиска по картинкам
Bing
Bingbot
Основной краулер Bing
MSNBot
Старый, но всё ещё использующийся краулер Bing
MSNBot-Media
Краулер Bing для изображений
BingPreview
Отдельный краулер Bing для Snapshot-изображений
Яндекс
YandexBot
Основной индексирующий бот Яндекса
YandexImages
Бот Яндеса для поиска по изображениям
Baidu
Baiduspider
Главный поисковый робот Baidu
Baiduspider-image
Бот Baidu для картинок
Applebot
Краулер для Apple. Используется для Siri поиска и Spotlight
SEO-инструменты
AhrefsBot
Краулер сервиса Ahrefs
MJ12Bot
Краулер сервиса Majestic
rogerbot
Краулер сервиса MOZ
PixelTools
Краулер «Пиксель Тулс»
Другое
DuckDuckBot
Бот поисковой системы DuckDuckGo
Советы по использованию операторов
1. Заблокировать определённые типы файлов.
Этот приём активно используется, если у проекта настроено ЧПУ для всех страниц и документы с GET-параметрами точно являются дублями.
Заблокировать результаты поиска, но не саму страницу поиска.
Имеет ли значение регистр?
Определённо да. При указании правил Disallow / Allow, URL адреса могут быть относительными, но обязаны сохранять регистр.
Но сами директивы могут объявляться как с заглавной, так и с прописной: Disallow: или disallow: — без разницы. Исключение — Sitemap: всегда указывается с заглавной.
Как проверить robots.txt?
Есть множество сервисов проверки корректности файлов robots.txt, но, пожалуй, самые надёжные: Google Search Console и Яндекс.Вебмастер.
Для мониторинга изменений, как всегда, незаменим «Модуль ведения проектов»:
Контроль индексации на вкладке «Аудит» — динамика сканирования страниц сайта в Яндексе и Google.
Как Google интерпретирует спецификацию robots.txt
Роботы Google бывают двух типов. Одни (поисковые) действуют автоматически и поддерживают стандарт исключений для роботов (REP). Это означает, что перед сканированием сайта они скачивают и анализируют файл robots.txt, чтобы узнать, какие разделы сайта для них открыты. Другие контролируются пользователями (например, собирают контент для фидов) или обеспечивают их безопасность (например, выявляют вредоносное ПО). Они не следуют этому стандарту.
Что такое файл robots.txt
В файле robots.txt можно задать правила, которые запрещают поисковым роботом сканировать определенные разделы и страницы вашего сайта. Он создается в обычном текстовом формате и содержит набор инструкций.
Расположение и области действия файла
Правила, перечисленные в файле robots.txt, действительны только в отношении того хоста, где расположен файл, и протокола и номера порта, по которым доступен этот файл.
Примеры действительных URL файла robots.txt
Действителен для: http://www.example.com/
Недействителен для: http://www.example.com/
Эквивалентами IDN являются их варианты в кодировке Punycode. Ознакомьтесь также с документом RFC 3492.
ftp://example.com/robots.txt
Действителен для: ftp://example.com/
Недействителен для: http://example.com/
Действителен для: http://212.96.82.21/
Недействителен для: http://example.com/ (даже если сайт расположен по IP-адресу 212.96.82.21)
Недействителен для: http://example.com:81/
Действителен для: http://example.com:8181/
Недействителен для: http://example.com/
Обработка ошибок и коды статуса HTTP
От того, какой код статуса HTTP вернет сервер при обращении к файлу robots.txt, зависит, как дальше будут действовать поисковые роботы Google.
Обработка ошибок и коды статуса HTTP
2xx (успешно)
Получив один из кодов статуса HTTP, которые сигнализируют об успешном выполнении, робот Google начинает обрабатывать файл robots.txt, предоставленный сервером.
3xx (переадресация)
Google не обрабатывает логические перенаправления в файлах robots.txt (фреймы, JavaScript или метатеги refresh).
Поисковые роботы Google воспринимают все ошибки 4xx так, как если бы действительный файл robots.txt отсутствовал. При этом сканирование выполняется без ограничений.
Поскольку сервер не может дать определенный ответ на запрос файла robots.txt, Google временно интерпретирует ошибки сервера так, как если бы сайт был полностью заблокирован. Google будет пытаться просканировать файл robots.txt до тех пор, пока не получит код статуса HTTP, не связанный с ошибкой сервера. При появлении ошибки 503 (service unavailable) попытки будут повторяться достаточно часто. Если файл robots.txt недоступен более 30 дней, будут выполняться правила в его последней кешированной копии. Если такой копии нет, роботы Google будут действовать без ограничений.
Другие ошибки
Если файл robots.txt невозможно получить из-за проблем с DNS или сетью (слишком долгого ожидания, недопустимых ответов, разрыва соединения, ошибки поблочной передачи данных по HTTP), это приравнивается к ошибке сервера.
Кеширование
Содержание файла robots.txt обычно хранится в кеше не более суток, но может быть доступно и дольше в тех случаях, когда обновить кешированную версию невозможно (например, из-за истечения времени ожидания или ошибок 5xx ). Сохраненный в кеше ответ может передаваться другим поисковым роботам. Google может увеличить или уменьшить срок действия кеша в зависимости от значения атрибута max-age в HTTP-заголовке Cache-Control.
Формат файла
Добавляемая в начало файла robots.txt метка порядка байтов Unicode BOM игнорируется, как и недопустимые строки. Например, если вместо правил robots.txt Google получит HTML-контент, система попытается проанализировать контент и извлечь правила. Все остальное будет проигнорировано.
Если для файла robots.txt используется не UTF-8, а другая кодировка, Google может проигнорировать символы, не относящиеся к UTF-8. В таком случае правила из файла robots.txt не будут работать.
В настоящее время максимальный размер файла, установленный Google, составляет 500 кибибайт (КиБ). Контент сверх этого лимита игнорируется. Чтобы не превысить его, применяйте более общие директивы. Например, поместите все материалы, которые не нужно сканировать, в один каталог.
Синтаксис
Google поддерживает следующие поля:
user-agent
Строка user-agent определяет, для какого робота применяется правило. Полный список поисковых роботов Google и строк для различных агентов пользователя, которые можно добавить в файл robots.txt, вы можете найти здесь.
Значение строки user-agent обрабатывается без учета регистра.
disallow
Значение директивы disallow обрабатывается с учетом регистра.
allow
Директива allow определяет пути, которые могут сканироваться поисковыми роботами. Если путь не указан, она игнорируется.
Значение директивы allow обрабатывается с учетом регистра.
sitemap
Google, Bing и другие крупные поисковые системы поддерживают поле sitemap из файла robots.txt. Дополнительную информацию вы можете найти на сайте sitemaps.org.
Значение поля sitemap обрабатывается с учетом регистра.
Группировка строк и правил
Вы можете группировать правила, которые применяются для разных агентов пользователя. Просто повторите строки user-agent для каждого поискового робота.
В этом примере есть четыре группы правил:
Техническое описание группы вы можете найти в разделе 2.1 этого документа.
Приоритет агентов пользователей
Примеры
Сопоставление полей user-agent
Поисковые роботы выберут нужные группы следующим образом:
Группировка правил
Если в файле robots.txt есть несколько групп для определенного агента пользователя, выполняется внутреннее объединение этих групп. Пример:
Поисковые роботы объединяют правила с учетом агента пользователя, как указано в примере кода ниже.
Соответствие значения пути конкретным URL
Google, Bing, Yahoo и Ask поддерживают определенные подстановочные знаки для путей:
Не соответствует: /Fish.PHP
Порядок применения правил
Когда роботы соотносят правила из файла robots.txt с URL, они используют самое строгое правило (с более длинным значением пути). При наличии конфликтующих правил (в том числе с подстановочными знаками) выбирается то, которое предполагает наименьшие ограничения.
Ознакомьтесь с примерами ниже.
Примеры
http://example.com/page
Except as otherwise noted, the content of this page is licensed under the Creative Commons Attribution 4.0 License, and code samples are licensed under the Apache 2.0 License. For details, see the Google Developers Site Policies. Java is a registered trademark of Oracle and/or its affiliates.
Директивы Disallow и Allow: как использовать совместно и раздельно
В данной статье речь пойдет о самых популярных директивах Dissalow и Allow в файле robots.txt.
Disallow
Disallow – директива, запрещающая индексирование отдельных страниц, групп страниц, их отдельных файлов и разделов сайта(папок). Это наиболее часто используемая директива, которая исключает из индекса:
Примеры директивыDisallow вrobots.txt:
Правило Disallow работает с масками, позволяющими проводить операции с группами файлов или папок.
После данной директивы необходимо ставить пробел, а в конце строки пробел недопустим. В одной строке с Disallow через пробел можно написать комментарий после символа “#”.
Allow
В отличие от Disallow, данное указание разрешает индексацию определенных страниц, разделов или файлов сайта. У директивы Allow схожий синтаксис, что и у Disallow.
Хотя окончательное решение о посещении вашего сайта роботами принимает поисковая система, данное правило дополнительно призывает их это делать.
Примеры Allow в robots.txt:
Для директивы применяются аналогичные правила, что и для Disallow.
Совместная интерпретация директив
Поисковые системы используют Allow и Disallow из одного User-agent блока последовательно, сортируя их по длине префикса URL, начиная от меньшего к большему. Если для конкретной страницы веб-сайта подходит применение нескольких правил, поисковый бот выбирает последний из списка. Поэтому порядок написания директив в robots никак не сказывается на их использовании роботами.
На заметку. Если директивы имеют одинаковую длину префиксов и при этом конфликтуют между собой, то предпочтительнее будет Allow.
Пример robots.txt написанный оптимизатором:
Пример отсортированного файл robots.txt поисковой системой:
Пустые Allow и Disallow
Когда в директивах отсутствуют какие-либо параметры, поисковый бот интерпретирует их так:
Специальные символы в директивах
В параметрах запрещающей директивы Disallow и разрешающей директивы Allow можно применять специальные символы “$” и “*”, чтобы задать конкретные регулярные выражения.
Специальный символ “*” разрешает индексировать все страницы с параметром, указанным в директиве. К примеру, параметр /katalog* значит, что для ботов открыты страницы /katalog, /katalog-tovarov, /katalog-1 и прочие. Спецсимвол означает все возможные последовательности символов, даже пустые.
Примеры:
По стандарту в конце любой инструкции, описанной в Robots, указывается специальный символ “*”, но делать это не обязательно.
Пример:
Для отмены данного спецсимвола в конце директивы применяют другой спецсимвол – “$”.
Пример:
На заметку. Символ “$” не запрещает прописанный в конце “*”.
Пример:
Более сложные примеры:
Примеры совместного применения Allow и Disallow
Я всегда стараюсь следить за актуальностью информации на сайте, но могу пропустить ошибки, поэтому буду благодарен, если вы на них укажете. Если вы нашли ошибку или опечатку в тексте, пожалуйста, выделите фрагмент текста и нажмите Ctrl+Enter.
Руководство по Robots.txt: как создать и правильно настроить
Примерно 60% пользователей сталкивается с тем, что новый сайт имеет проблемы с продвижением в поиске из-за неправильно настроенного файла robots.txt. Поэтому не всегда стоит сразу после запуска вкладывать все ресурсы в SEO-тексты, ссылки или внешнюю рекламу, так как некорректная настройка одного единственного файла на сайте способна привести к фатальным результатам и полной потере трафика и клиентов. Однако, всего этого можно избежать, правильно настроив индексацию сайта, и сделать это можно даже не будучи техническим специалистом или программистом.
Что такое файл robots.txt?
Robots.txt это обычный текстовый файл, содержащий руководство для ботов поисковых систем (Яндекс, Google, etc.) по сканированию и индексации вашего сайта. Таким образом, каждый поисковый бот (краулер) при обходе страниц сайта сначала скачивает актуальную версию robots.txt (обновляет его содержимое в своем кэше), а затем, переходя по ссылкам на сайте, заносит в свой индекс только те страницы, которые разрешены к индексации в настройках данного файла.
При этом у каждого краулера существует такое понятие, как «краулинговый бюджет», определяющее, сколько страниц можно просканировать единоразово (для разных сайтов это значение варьируется: обычно в зависимости от объема и значимости сайта). То есть, чем больше страниц на сайте и чем популярнее ресурс, тем объемнее и чаще будет идти его обход краулерами, и тем быстрее эти данные попадут в поисковую выдачу (например, на крупных новостных сайтах поисковые боты постоянно сканируют контент на предмет поиска новой информации (можно сказать что «живут»), за счет чего поисковая система может выдавать пользователем самые актуальные новости уже через несколько секунд после их публикации на сайте).
Таким образом, из-за ограниченности краулингового бюджета рекомендуется отдавать поисковым ботам в приоритете только ту информацию, которая должна обновляться или появляться в индексе поисковиков наиболее быстро (например, важные, полезные и актуальные страницы сайта), а все прочее устаревшее и не нужное можно смело скрывать, тем самым не распыляя краулинговый бюджет на не имеющий ценности контент.
Вывод: для оптимизации индексирования сайта стоит исключать из сканирования дубликаты страниц, результаты локального поиска по сайту, личный кабинет, корзину, сравнения, сортировки и фильтры, пользовательские профили, виш-листы и всё, что не имеет ценности для обычного пользователя.
Как найти и просмотреть содержимое robots.txt?
Файл размещается в корне домена по адресу somesite.com/robots.txt.
Данный метод прост и работает для всех веб-ресурсов, на которых размещен robots.txt. Доступ у файла открытый, поэтому каждый может просмотреть файлы других сайтов и узнать, как они настроены. Просто допишите «/robots.txt» в конец адресной строки интересующего домена, и вы получите один из двух вариантов:
Вывод: если на вашем ресурсе по адресу /robots.txt вы получаете ошибку 404, то этот момент однозначно стоит исправить (создать, настроить и добавить файл на сервер).
Создание и редактирование robots.txt
Примечания:
Структура и синтаксис robots.txt
Существуют стандартные директивы разрешения или запрета индексации тех ли иных страниц и разделов сайта:
В данном примере всем поисковым ботам не разрешается индексировать сайт (слеш через : и пробел от директивы Disallow указывает на корень сайта, а сама директива – на запрет чего-либо, указанного после двоеточия). Звездочка говорит о том, что данная секция открыта для всех User-agent (у каждой поисковой машины есть свой юзер-агент, которым она идентифицируется. Например, у Яндекса это Yandex, а у Гугла – Googlebot).
А, например, такая конструкция:
Говорит о том, что роботам Гугл разрешено индексировать весь сайт (для остальных поисковых систем директив в данном примере нет, поэтому если для них не прописаны какие-либо запрещающие правила, значит индексирование также разрешено).
Здесь роботам Яндекса запрещено индексировать личные профили пользователей (папка somesite.com/profile/), все остальное на сайте разрешено. А, например, роботу гугла разрешено индексировать вообще все на сайте.
Как вы уже могли догадаться, знак решетка «#» используется для написания комментариев.
Пример для запрета индексации конкретной страницы, входящей в блок типовых страниц:
Данная директива запрещает индексацию раздела /profile/, однако разрешает индексацию всех его подразделов и отдельных страниц:
Директива User-agent
Это обязательное поле, являющееся указанием поисковым ботам для какого поисковика настроены данные директивы. Звездочка (*) означает то, что директивы указаны для всех сканеров от всех поисковиков. Либо на ее месте может быть вписано конкретное имя поискового бота.
Это будет работать до тех пор, пока в файле не встретятся инструкции для другого User-agent, если для него есть отдельные правила.
Директива Disallow
Как мы писали выше, это директива запрета индексации страниц и разделов на вашем сайте по указанным критериям.
Пример запрета индексации PDF и файлов MS Word и Excel:
В данном случае, звездочка играет роль любой последовательности символов, то есть к индексации будут запрещены файлы формата: pdf, doc, xls, docx, xlsx.
Примечание: для ускорения удаления из индекса недавно запрещенных к индексации страниц можно прибегнуть к помощи панели Яндекс Вебмастера: Удалить URL. Для группового удаления страниц и разделов нужно перейти в раздел «Инструменты» конкретного сайта и уже там выбрать режим «По префиксу».
Директивы Allow, Sitemap, Clean-param, Crawl-delay и другие
Дополнительные директивы предназначены для более тонкой настройки robots.txt.
Allow
Как противоположность Disallow, Allow дает указание на разрешение индексации отдельных элементов.
Яндекс может проиндексировать сайт целиком, остальным поисковым системам сканирование запрещено.
Либо, к примеру, мы можем разрешить к индексации отдельные папки и файлы, запрещенные через Disallow.
Sitemap.xml
Это файл для прямого указания краулерам списка актуальных страниц на сайте. Данная карта сайта предназначена только для поисковых роботов и оформлена специальным образом (XML-разметка). Файл sitemap.xml помогает поисковым ботам обнаружить страницы для дальнейшего индексирования и должен содержать только актуальные страницы с кодом ответа 200, без дублей, сортировок и пагинаций.
Стандартный путь размещения sitemap.xml – также в корневой папке сайта (хотя в принципе она может быть расположена в любой директории сайта, главное указать правильный путь к sitemap):
Для крупных порталов карт сайта может быть даже несколько (Google допускает до 1000), но для большинства обычно хватает одного файла, если он удовлетворяет ограничениям:
Если ваш файл превышает указанный размер в 50 мегабайт, или же URL-адресов, содержащихся в нем, более 50 тысяч, то вам придется разбить список на несколько файлов Sitemap и использовать файл индекса для указания в нем всех частей общего Sitemap.
Примечание: параметр Sitemap – межсекционный, поэтому может быть указан в любом месте файла, однако обычно принято прописывать его в последней строке robots.txt.
Clean-param
Если на страницах есть динамические параметры, не влияющие на контент, то можно указать, что индексация сайта будет выполняться без учета этих параметров. Таким образом, поисковый робот не будет несколько раз загружать одну и ту же информацию, что повышает эффективность индексации.
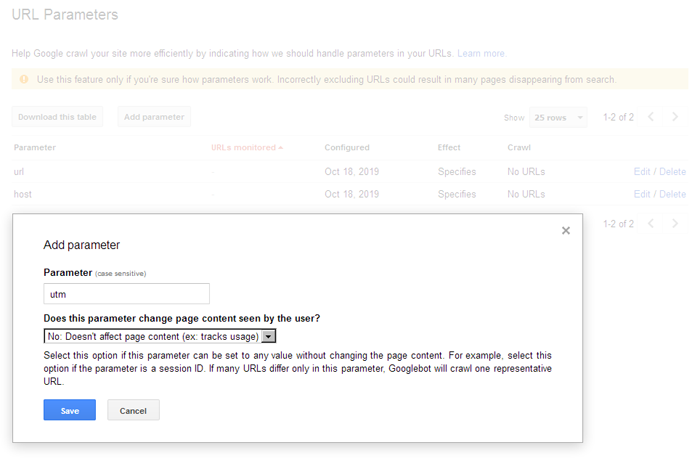
К примеру, «Clean-param: highlight /forum/showthread.php» преобразует ссылку «/forum/showthread.php?t=30146&highlight=chart» в «/forum/showthread.php?t=30146» и таким образом не будет добавлять дубликат страницы форума с параметром подсветки найденного текста в ветке форума.
Clean-param используется исключительно для Яндекса, Гугл же использует настройки URL в Google Search Console. У гугла это осуществляется намного проще, простым добавлением параметров в интерфейсе вебмастера:
Crawl-delay
Данная инструкция относится к поисковой системе Яндекс и указывает правила по интенсивности его сканирования поисковым роботом. Это бывает полезно, если у вас слабый хостинг и роботы сильно нагружают сервер. В таком случае, вы можете указать им правило сканировать сайт реже, прописав интервалы между запросами к веб-сайту.
К примеру, Crawl-delay: 10 – это указание сканеру ожидать 10 секунд между каждым запросом. 0.5 – пол секунды.
Robots.txt для WordPress
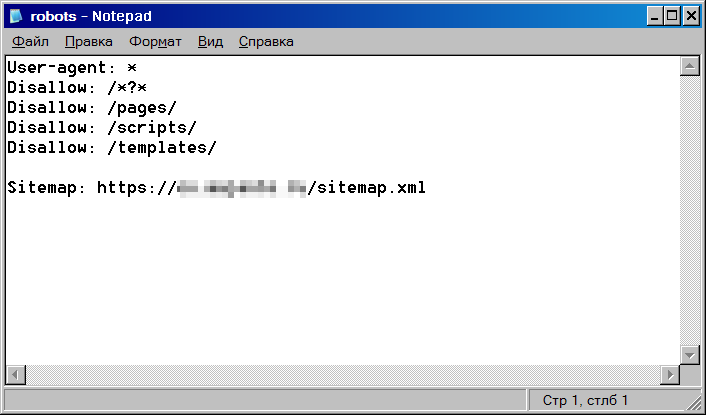
Ниже выложен пример robots.txt для сайта на WordPress. Стандартно у Вордпресс есть три основных каталога:
Папка /wp-content/ содержит подпапку «uploads», где обычно размещены медиа-файлы, и этот основной каталог целиком блокировать не стоит:
Данный пример блокирует выбранные служебные папки, но при этом позволяет сканировать подпапку «uploads» в «wp-content».
Настройка robots.txt для Google и Яндекс
Желательно настраивать директивы для каждой поисковой системы отдельно, как минимум, их стоит настроить для Яндекса и Гугл, а для остальных указать стандартные значения со звездочкой *.
Настройка robots.txt для Яндекса
В некоторых роботс иногда можно встретить устаревшую директиву Host, предназначенную для указания основной версии (зеркала) сайта. Данная директива устарела, поэтому ее можно не использовать (теперь поисковик определяет главное зеркало по 301-м редиректам):
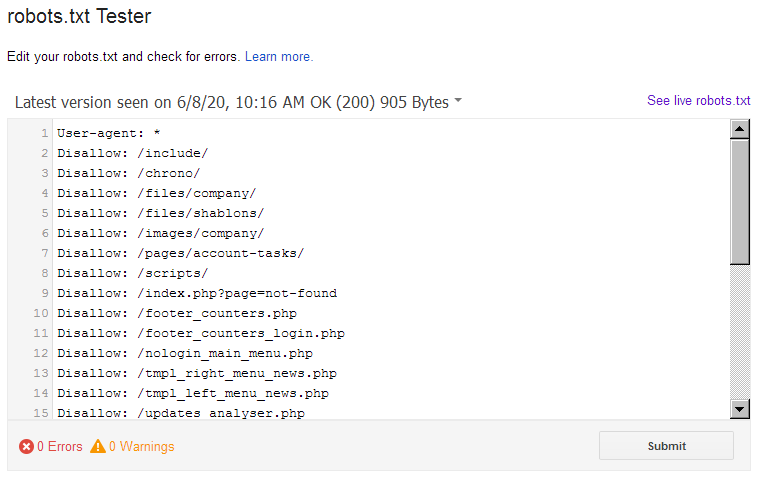
Воспользуйтесь бесплатным инструментом Яндекса для автоматической проверки корректности настроек роботса.
Настройка robots.txt для Google
Принцип здесь тот же, что и у Яндекса, хоть и со своими нюансами. К примеру:
Важно: для Google мы добавляем возможность индексации CSS-таблиц и JS, которые важны именно для этой поисковой системы (поисковик умеет рендерить яваскрипт, соответственно может получить из него дополнительную информацию, имеющую пользу для сайта, либо просто для понимания, для чего служит тот или ной скрипт на сайте).
По ссылке в Google Webmaster Tools вы можете убедиться, правильно ли настроен ваш robots.txt для Гугла.
Запрет индексирования через Noindex и X-RobotsTag
В некоторых случаях, поисковая система Google может по своему усмотрению добавлять в индекс страницы, запрещенные к индексации через robots.txt (например, если на страницу стоит много внешних ссылок и размещена полезная информация).
Для 100% скрытия нежелаемых страниц от индексации, используйте мета-тег NOINDEX.
Noindex – это мета-тег, который сообщает поисковой системе о запрете индексации страницы. В отличие от роботса, он является более надежным, поэтому для скрытия конфиденциальной информации лучше использовать именно его:
Чтобы скрыть страницу только от Google, укажите:
X-Robots-Tag
Тег x-robots позволяет вам управлять индексированием страницы в заголовке HTTP-ответа страницы. Данный тег похож на тег meta robots и также не позволяет роботам сканировать определенные виды контента, например, изображения, но уже на этапе обращения к файлу, не скачивая его, и, таким образом, не затрачивая ценный краулинговый ресурс.
Примечание: X-Robots-Tag эффективнее, если вы хотите запретить сканирование изображений и медиа-файлов. Применимо к контенту лучше выбирать запрет через мета-теги. Noindex и X-Robots Tag это директивы, которым поисковые роботы четко следуют, это не рекомендации как robots.txt, которые по определению можно не соблюдать.
Как быстро составить роботс для нового сайта с нуля?
Очень просто – скачать у конкурента! )
Просто зайдите на любой интересующий сайт и допишите в адресную строку /robots.txt, — так вы увидите, как это реализовано у конкурентов. При этом не стоит бездумно копировать их содержимое на свой сайт, ведь корректно настроенные директивы чужого сайта могут негативно подействовать на индексацию вашего веб-ресурса, поэтому желательно хотя бы немного разбираться в принципах работы роботс.тхт, чтобы не закрыть доступ к важным разделам.
И главное: после внесения изменений проверяйте robots.txt на валидность (соответствие правилам). Тогда вам точно не нужно будет опасаться за корректность индексации вашего сайта.